

Insights into AI Benchmarking with Release of Llama 3.1
Explore Meta’s strategic vision with Llama 3.1, focusing on the benchmarks that demonstrate its commitment to leading the AI industry through innovation and open-source accessibility

Hello, fellow tech enthusiasts and AI stalkers! Welcome back to another insightful episode of Tech Trendsetters, where we explore the latest advancements shaping our tech world, be it technology, science, or artificial intelligence.
Today, we turn our spotlight on the highly anticipated release of Llama 3.1, the latest major news in large language models (LLMs). Llama 3.1 promises to reach new heights in the AI world, boasting unparalleled performance, scalability, and versatility. Alongside this exciting release, we also gain new insights into how LLM evaluations actually happen and review Meta’s company strategy for the years to come. Let’s get started!
Llama 3.1

In April 2024, Meta introduced Llama 3, the next generation of modern open-source large language models. The first two models, Llama 3 8B and Llama 3 70B, set new standards for LLMs in their size. However, just three months after their release, several other LLMs outperformed them.
Today, July 2024, Meta has officially released its new Llama 3.1 models.
And this release is generating quite a bit of discussion online. Some headlines are even suggesting it might "bury ChatGPT," though I think that's probably an overstatement. Still, there's no denying that this release is significant.
Democratizing Cutting-Edge AI
Llama 3.1 is the first frontier-level open-source AI model. And this is a big deal, folks. Why? Because open-source models democratize access to cutting-edge AI technology. Traditionally, the most advanced AI models have been closely guarded by tech giants, accessible only through paid APIs or limited partnerships. With Llama 3.1, we're seeing a paradigm shift.
Researchers, developers, and companies of all sizes can now access, study, and build upon a state-of-the-art language model without the constraints of proprietary licenses or exorbitant costs. This opens up a world of possibilities for innovation and experimentation.
A Range of Models for Different Needs
Meta hasn't just released one model; they've introduced a whole family of Llama 3.1 models (some of which already present on HuggingFace):
Meta-Llama-3.1-8B
Meta-Llama-3.1-70B
Meta-Llama-3.1-405B
Each of these models comes with different capabilities and resource requirements, allowing developers to choose the one that best fits their needs and computational resources. They've also released fine-tuned versions, including "Instruct" variants and specialized models like Llama-Guard-3-8B for enhanced safety and security.
The 405B Powerhouse
The crown jewel of this release is undoubtedly the 405 billion parameters model. It's a behemoth in terms of scale and capabilities, rivaling some of the best closed-source models out there. But with great power comes great computational requirements. To address this, Meta has provided several versions of the 405B model:
An MP16 version that needs at least two nodes with 8 GPUs each';
An MP8 version for a single node with 8 GPUs using FP8 dynamic quantization;
An FP8 version, which is a more compact option;
This flexibility ensures that researchers and developers with varying resources can work with the model, even further democratizing access to advanced AI.
Immediate Availability and Ecosystem Support
What's particularly exciting is that API providers have already started offering the Llama 3.1 405B model in their services. At the moment, it's the most affordable and cheap frontier model available. There's a good chance we'll see prices drop further as providers compete, which could make advanced AI more accessible to developers and researchers.
Moreover, Meta has partnered with over 25 companies, including tech giants like AWS, NVIDIA, Google Cloud, and Microsoft Azure, to offer services and support for Llama 3.1 from day one. This robust ecosystem ensures that developers can hit the ground running with the new models.
Some Technical Facts Behind Llama 3.1
Training the 405B model on over 15 trillion tokens was definetely no small feat. Meta pushed their model training to over 16,000 H100 GPUs, making it the first open sourced model trained at this scale.
By the way, slightly off-topic, but Elon Musk recently announced that they finished building the data center that houses 100,000 H100 GPU chips. They are dedicated to training the new version of Grok by December 2024. You can imagine how much more compute power Elon has now.
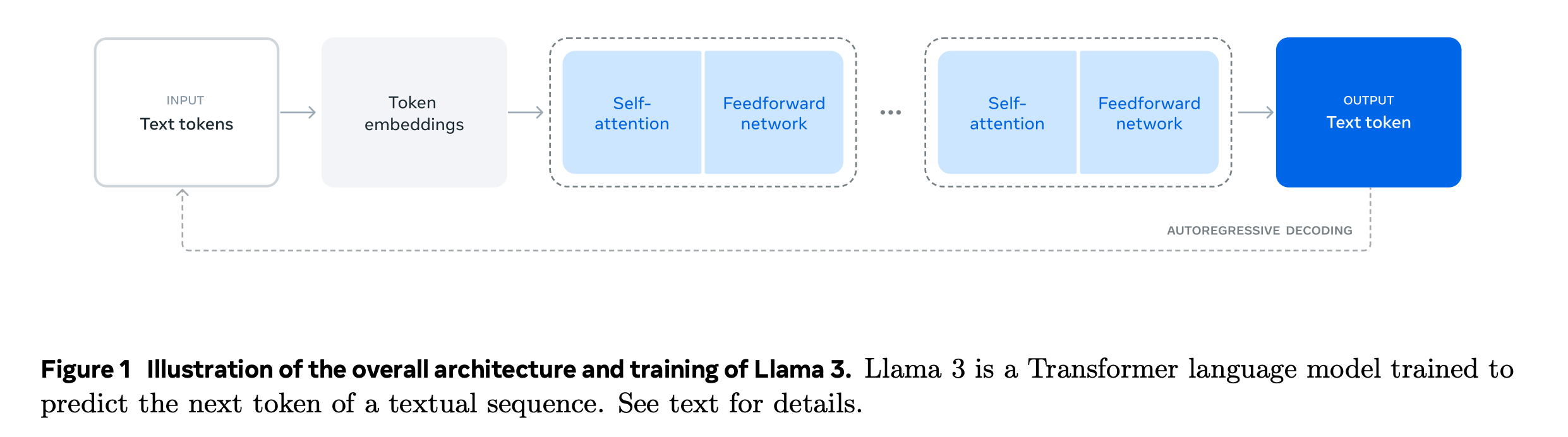
Meta opted for a standard decoder-only transformer model architecture with minor adaptations, rather than a mixture-of-experts model. This choice was made to maximize training stability. They also adopted an iterative post-training procedure, using supervised fine-tuning and direct preference optimization to create high-quality synthetic data and improve performance across capabilities.
Overall, that means Meta decided to use a simpler, more reliable type of artificial intelligence (AI) model. Instead of combining many different models, they used a single, consistent model that is easier to train and less likely to encounter problems.
Compared to previous Llama versions, Meta improved both the quantity and quality of data used for pre- and post-training. This included developing more careful pre-processing and curation pipelines for pre-training data, as well as more rigorous quality assurance and filtering approaches for post-training data.
The post-training process for Llama 3.1 involved several rounds of alignment, including Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO). They used synthetic data generation to produce the majority of their SFT examples, iterating multiple times to produce higher quality synthetic data across all capabilities.
Llama 3.1 uses a new tokenizer with a vocabulary of 128,000 tokens, which is the massive leap from previous models that had 8k tokens, combining 100,000 tokens from the tiktoken tokenizer with 28,000 additional tokens to better support non-English languages. This new tokenizer improves compression rates on English data from 3.17 to 3.94 characters per token, allowing the model to process more text with the same computational resources.
While the core Llama 3.1 model focuses on text, Meta also conducted experiments to incorporate visual and audio recognition capabilities using a compositional approach. These multimodal experiments resulted in models capable of recognizing content in images and videos, and supporting interaction via a speech interface. However, Meta notes that these multimodal models are still under development and not yet ready for release.
How to Read LLM Benchmarks
While Llama 3.1's technical specs and the democratization of AI access are incredibly exciting, understanding the true impact of these advancements requires a closer look at how these models are evaluated. This brings us to the crucial aspect of reading and interpreting LLM benchmarks.
Despite the noise surrounding Llama 3.1, I know only a few people who truly grasp what these numbers and benchmarks actually mean. To bridge this knowledge gap, let's learn how to read and interpret LLM benchmarks for your particular purpose.


Benchmarks are standardized tests designed to measure the performance of language models across various tasks. They serve several key purposes:
Allowing researchers and developers to objectively compare different models;
Monitoring advancements in AI over time and comparing the progress of different versions of the same models;
Identifying strengths and weaknesses, revealing where models excel and where they need improvement;
It's important to note that evaluating language models involves a range of benchmarks, each testing different aspects of performance. These benchmarks provide a way to compare models and understand their capabilities in different contexts. However, no single benchmark tells the complete story of a model's abilities.
As you can see in the picture above, Llama 3.1 was evaluated and tested on 15 different benchmarks. Let’s break them down:
General Benchmarks:
MMLU (Massive Multitask Language Understanding): A comprehensive benchmark designed to evaluate language models across a diverse range of subjects, testing their ability to understand and reason through various academic disciplines. This benchmark covers 57 topics including mathematics, history, law, and medicine, comprising over 14,000 multiple-choice questions. The questions span from elementary to advanced levels, challenging models to demonstrate extensive world knowledge and problem-solving abilities. MMLU rigorously assesses both knowledge recall and application, making it a robust measure of a model's general academic proficiency and reasoning capabilities.
Llama 3.1 Score: 88.6 – Impressively close to the top performer, just 0.1 points behind GPT-4 Omni!
MMLU PRO: Extends basic MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. This new benchmark eliminates trivial and noisy questions and focuses on complex, graduate-level problems requiring deeper reasoning capabilities. Features more deliberate reasoning across various domains, including mathematics, physics, chemistry, law, engineering, psychology, and health, with over 12,000 questions. The benchmark presents a significant challenge, with leading models experiencing a notable drop in accuracy compared to the original MMLU. Moreover, MMLU-Pro demonstrates greater stability under varying prompts and requires models to use chain of thought (CoT) reasoning for better performance, highlighting the inclusion of more complex reasoning questions.
Llama 3.1 Score: 73.3 – Showing strong performance, not far behind the leaders in this tougher scenario. GPT4o has 74.0 on that test.
IFEval (Instruction-Following Eval): A benchmark designed to objectively evaluate LLMs ability to follow natural language instructions. This benchmark focuses on "verifiable instructions" that can be objectively checked for compliance. Examples of such instructions include "write in more than 400 words" and "mention the keyword of AI at least 3 times." IFEval includes 25 types of verifiable instructions and around 500 prompts, each containing one or more verifiable instructions. The evaluation involves verifying if the model's responses meet these specific criteria, providing a standardized, unbiased, and automatic assessment method.
Llama 3.1 Score: 88.6 – Demonstrating the best performance in following verifiable instructions, overcoming all other top performers in this objective evaluation benchmark.
Code Benchmarks:
HumanEval: Evaluation set specifically designed to measure the functional correctness of language models in synthesizing programs from docstrings. The benchmark consists of 164 hand-written programming problems, each accompanied by a function signature, a detailed docstring, and several unit tests. These problems assess various skills, including language comprehension, algorithms, and basic mathematics. The evaluation process involves generating multiple samples from the models and checking if any of them pass the unit tests. This benchmark is unique in its focus on generating standalone Python functions from natural language descriptions and using unit tests to automatically evaluate the correctness of the generated code.
Llama 3.1 Score: 89.0 – Impressive performance, though slightly behind GPT-4 Omni and Claude 3.5 Sonnet.
MBPP EvalPlus (Mostly Basic Python Problems): This benchmark is an extension of the MBPP dataset, designed to evaluate the Python coding skills of language models. It includes a diverse range of programming tasks, from basic to intermediate difficulty, aimed at assessing the functional correctness of generated code snippets. The benchmark employs both language model-based and mutation-based strategies to generate a high volume of diverse test cases, ensuring comprehensive testing. EvalPlus also incorporates test-suite reduction techniques to manage test execution cost while maintaining effectiveness. Each task is annotated with program contracts to filter out invalid inputs and clarify expected behaviors.
Llama 3.1 Score: 88.6 – Strong performance in Python programming tasks, keeping pace with the top models – beats GTP-4o, but not Claude.
Math Benchmarks:
GSM8K (Grade School Math 8K): A dataset of 8.5K high-quality, linguistically diverse grade school math word problems designed to evaluate the ability of language models to perform multi-step mathematical reasoning. Despite the conceptual simplicity of the problems, state-of-the-art models struggle to achieve high test performance. The benchmark highlights the sensitivity of models to individual mistakes, as solutions that veer off course quickly become unrecoverable. GSM8K includes problems that require elementary calculations and basic arithmetic operations (+−×÷), with solutions provided in natural language to shed light on the reasoning process. The introduction of verifiers to judge the correctness of model-generated solutions has shown significant improvement in performance, demonstrating that verification scales more effectively with increased data compared to finetuning alone.
Llama 3.1 Score: 96.8 – The best performance in solving these challenging math problems, slightly edging out even GPT-4 Omni!
MATH (Mathematics Aptitude Test of Heuristics): A dataset of 12,500 challenging competition mathematics problems designed to measure the mathematical problem-solving abilities of machine learning models. Each problem in MATH is accompanied by a detailed step-by-step solution, enabling models to learn to generate derivations and explanations for their answers. The problems span various subjects, including algebra, geometry, number theory, and calculus, and are categorized by difficulty levels from 1 to 5. This benchmark is uniquely difficult due to the need for advanced problem-solving techniques and heuristics rather than straightforward calculations. Despite pretraining and fine-tuning, many large models still show relatively low accuracy on MATH.
Llama 3.1 Score: 73.8 – Outstanding performance on this challenging dataset, slightly outperforming Claude 3.5 Sonnet, but still behind GPT-4 Omni.
Reasoning Benchmarks:
ARC Challenge (AI2 Reasoning Challenge): Designed in 2018 by Clark et al., the AI2 Reasoning Challenge (ARC) is a benchmark aimed at evaluating the knowledge and reasoning capabilities of language models. It consists of 7787 non-diagram, multiple-choice science questions intended for 3rd to 9th grade-level standardized tests. The questions are divided into an "Easy Set" and a "Challenge Set." The Challenge Set includes 2590 questions that were incorrectly answered by retrieval-based and word co-occurrence algorithms, making them particularly difficult and requiring advanced reasoning and comprehension skills. The ARC Corpus, containing 14 million sentences relevant to the questions, aids in training or fine-tuning models without allowing memorization of answers. Scoring is based on correctness and k-way ties, with the Challenge Set designed to push models beyond simple fact retrieval to deeper understanding and reasoning.
Llama 3.1 Score: 96.9 – Top-tier logical reasoning, slightly outperforming other models!
GPQA (Graduate-Level Google-Proof Q&A Benchmark): A rigorous dataset consisting of 448 multiple-choice questions meticulously crafted by domain experts in biology, physics, and chemistry. The questions are intentionally challenging, with human experts achieving 65% accuracy (74% when accounting for clear mistakes), while highly skilled non-experts with unrestricted web access only achieve 34% accuracy. This "Google-proof" benchmark tests the limits of both human and AI problem-solving abilities. GPQA's questions are designed to be difficult for state-of-the-art AI systems, pushing the boundaries of knowledge extraction and reasoning in graduate-level scientific domains. The benchmark emphasizes the need for scalable oversight methods, ensuring that AI systems can provide reliable answers even in complex, specialized fields.
Llama 3.1 Score: 51.1 – Impressively outperforming both non-expert humans and some AI baselines on this extremely challenging benchmark.
Tool Use Benchmarks:
BFCL (Berkeley Function-Calling Leaderboard): The first comprehensive benchmark to evaluate the function-calling capabilities of large language models. It consists of 2,000 question-function-answer pairs covering various programming languages such as Python, Java, JavaScript, and SQL, and different application scenarios, including simple, parallel, and multiple function calls. BFCL assesses the models' abilities to select, execute, and verify function calls, and handle irrelevant functions without hallucinating. The leaderboard includes both accuracy and performance metrics like cost and latency, making it a robust tool for evaluating function-calling models.
Llama 3.1 Score: 88.5 – Highly capable in utilizing tools, outperforming GPT-4 Omni! Almost as good as Claude 3.5 Sonnet.
Nexus (Nexus Function Calling Benchmark): A comprehensive evaluation dataset featuring 9 tasks based on real-world APIs, with 8 publicly released. It assesses LLMs' function-calling abilities across three categories: single calls, nested calls, and parallel calls. The benchmark includes diverse APIs like NVDLibrary, VirusTotal, OTX, Places API, and Climate API, providing insights into models' capabilities in handling various API usage scenarios.
Llama 3.1 Score: 58.7 – Solid performance, outpacing all other models like GPT-4o and Claude 3.5 Sonnet. This benchmark helps evaluate how well models can integrate with and utilize real-world APIs, from simple single-call scenarios to more complex nested and parallel call situations.
Long Context Benchmarks:
ZeroSCROLLS/QuaLITY (Zero-Shot CompaRison Over Long Language Sequences): ZeroSCROLLS is a benchmark designed to evaluate the zero-shot capabilities of LLMs in understanding and reasoning over long texts. This benchmark consists of ten tasks adapted from the Scrolls benchmark and four new datasets, including query-based summarization, multi-hop question answering, sentiment aggregation, and sorting book chapter summaries. ZeroSCROLLS includes only test and small validation sets, with no training data, and covers domains such as government reports, TV show scripts, academic meetings, literature, and scientific papers. The benchmark highlights the challenges models face in aggregation tasks and promotes research in instruction understanding, prompt engineering, and evaluation of generated texts.
Llama 3.1 Score: 95.2 – Excellent at handling long context scenarios, achieving the best score across all tasks. Excellent performance in understanding and reasoning over extended text sequences.
InfiniteBench/En.MC: Benchmark designed to evaluate the performance of language models in handling extremely long context scenarios, extending beyond 100K tokens. This benchmark includes tasks from various domains such as document comprehension, agent construction, and long-term reasoning. It is specifically designed to test the models' ability to process, understand, and reason over long sequences of text, ensuring that they can maintain coherence and provide accurate responses over extended contexts. The tasks include complex retrieval, such as locating specific keys within noisy contexts or retrieving values from large JSON objects, and code execution tasks that require models to simulate multi-step functions and manage long-term state tracking.
Llama 3.1 Score: 83.4 – Again, the best of all, demonstrating exceptional ability to handle and reason over extremely long contexts.
NIH/Multi-needle (Multi-Needle in a Haystack): Benchmark designed to evaluate the performance of long-context LLMs in retrieving and reasoning over multiple facts embedded within extensive contexts. It extends the concept of the "Needle in a Haystack" benchmark, where a single fact (needle) is injected into a large body of context (haystack), by testing models on multiple facts and their subsequent reasoning capabilities.
Llama 3.1 Score: 98.1 – Nearly perfect in dealing with long context information, though slightly behind GPT-4 models. Interestingly, GPT-4 and GPT-4o both have a maximum score of 100 in such tests, which may indicate something anomalous.
Multilingual Benchmark:
Multilingual MGSM (The Multilingual Grade School Math): Benchmark evaluates the reasoning abilities of large language models in multilingual settings. It extends the GSM8K dataset by translating 250 grade-school math problems into ten typologically diverse languages. MGSM assesses models' ability to solve math problems through chain-of-thought prompting, showing significant multilingual reasoning abilities, even in underrepresented languages like Bengali and Swahili. This benchmark also demonstrates that multilingual reasoning extends to other tasks such as commonsense reasoning and word-in-context semantic judgment.
Llama 3.1 Score: 91.6 – Excels in multilingual math problem-solving, matching Claude 3.5 Sonnet and outperforming GPT-4 models!
All benchmarks can be executed with three main approaches: zero-shot, few-shot (such as five-shot), and chain-of-thought (CoT) prompting. You can also see it on the benchmark overview pictures that one or multiple techniques is applied.
Zero-Shot: Zero-shot learning refers to the ability of a model to perform a task without having been explicitly trained on examples of that task. Specifically, zero-shot performance means the model can understand and respond to new types of questions or tasks using only its pre-existing knowledge, without needing specific examples. For instance, if a model is asked to translate a sentence into a language it hasn't been trained on, its success in doing so would be a measure of its zero-shot capability.
Few-Shot: Model is given few examples of a task before being asked to perform it. This approach helps the model understand the task better by providing a small number of relevant examples, which can be particularly useful for tasks that are not well-covered in the model's training data. By seeing these, let’s say five examples, the model can generalize and apply the learned patterns to new, similar instances.
Chain-of-Thought (CoT): Chain-of-thought prompting is a technique where a model is encouraged to explain its reasoning process step-by-step while solving a problem. This approach aims to improve the model's performance on complex tasks that require logical reasoning and multi-step problem solving. By breaking down the problem into smaller, manageable steps and articulating each step, the model can better understand and solve the problem. CoT prompting can be particularly effective in tasks like mathematical problem-solving or logical reasoning, where intermediate steps are crucial to arriving at the correct solution.
So what do we finally have to conclude from all these benchmarks?
Just looking at these numbers, I'm astounded by Llama 3.1's performance. The 405B parameter model isn't just keeping up with the likes of GPT-4 and Claude – it's actually beating them in many tasks. Sure, it's not dominating across the board, but the fact that it's outperforming these industry giants in several benchmarks is nothing short of remarkable.
But here's what really important: the smaller Llama 3.1 models. The 8B and 70B versions are absolute game-changers. They're not just holding their own; they're completely dominating in domains where GPT-3.5 once reigned supreme. Remember when we thought GPT-3.5 was the best we could imagine? Those days seem like ancient history now.
Finally, we're entering an era where AI capabilities that once required massive computational resources are becoming accessible to a much wider audience. And the cherry on top? Llama 3.1 is open-sourced.
Why Meta is Betting on Open-Source
Now let’s shift our attention back to Meta. It is quite natural to ask why Meta, investing heavily in development, relies on open source code, making Llama available to almost everyone (with a caveat for large companies). Mark Zuckerberg, explaining the company's motivations, draws a parallel with Linux, the open operating system that powers the vast majority of devices today. He argues that open source models have a significant development advantage because they can be improved by a wide range of developers.
I believe the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source
– Zuckerberg said.
I would bet that Meta's commitment to open source AI is rooted in several key beliefs, that he has expressed over the past years:
By making Llama 3.1 open source, Meta is lowering barriers to entry for AI research and development. Like with any open sourced software, this allows a broader range of developers, researchers, and companies to access and build upon cutting-edge AI technology;
Open source models can be improved by a wide range of developers, potentially leading to faster advancements than closed systems. This collaborative approach mirrors the success of Linux in the operating system space;
Organizations can train, fine-tune, and distill Llama models to meet their specific needs without relying on or sharing data with external providers;
Open source models can be run locally, addressing concerns about data privacy and security that come with using cloud-based APIs for closed models;
Llama 3.1 models, particularly the 405B version, offer competitive performance at a lower cost compared to closed alternatives;
Open sourcing Llama encourages the growth of a diverse ecosystem of tools, services, and applications built around the model.
Meta's Business Strategy
Given all provided information, we can see that Meta's business model isn't about selling access to AI models. Instead, the company aims to ensure it always has access to the best technology without being locked into competitors' closed ecosystems. By open sourcing Llama, Meta is fostering an ecosystem that can potentially become the industry standard, benefiting its own services and own success in the long run.
While some worry about the safety implications of open source AI, Zuckerberg argues that it can actually be safer than closed alternatives. Open models are subject to wider scrutiny, potentially leading to faster identification and mitigation of risks.
Zuckerberg positions open source AI as crucial for a positive AI future, ensuring broader access to AI benefits and preventing power concentration. He also argues that open innovation is key to maintaining a competitive edge against geopolitical adversaries, rather than relying on closed systems that can be compromised through espionage.
In 2021, Mark Zuckerberg rebranded Facebook as Meta, confidently betting on the metaverse as the future. Fast forward four years, and here we are, still waiting for that metaverse to materialize. Clearly, this grand vision hasn't materialized as quickly as anticipated. However, Meta's pivot to AI, particularly its commitment to open-source models like Llama 3.1, suggests a strategic realignment.
Despite the fact that Meta does not disclose the exact popularity figures of Meta AI, Mark Zuckerberg expresses confidence that by the end of the year their AI assistant will surpass the 100 million ChatGPT users in popularity. This bold prediction underscores Meta's commitment to becoming a major player in the AI space, leveraging its vast user base across its social media platforms to drive adoption of its AI tools.
The company's ambitious AI goals are further emphasized by Ahmad Al-Dahle, Meta's vice president of generative AI, who notes, "We are still at the beginning of the journey." This statement suggests that Meta views its current AI offerings as just the tip of the iceberg, with hopefully much more innovation on the horizon.
Overall, Meta's business strategy has undergone a significant evolution in recent years. While the company's core business model isn't centered on selling AI products or the Metaverse, its approach to technology development has shifted dramatically. The open-sourcing of Llama with 405B parameters represents a strategic move to foster an ecosystem that could become the industry standard, ultimately benefiting Meta's services and long-term success. We will monitor closely how that happens.
Thanks for being with me for this reading! Today we learned how Llama 3.1 marks a new cycle in LLM evolution, showcasing impressive capabilities across various benchmarks.
Open-source nature sets it apart. Meta's decision to make this model freely available opens up new possibilities for researchers, developers, and companies of all sizes, potentially accelerating innovation and democratizing access to advanced AI technology.
Today is the day when you can finally run an LLM competitive with GPT-4o at home with the right hardware! And this is a significant milestone.
Keep learning and applying new models into practice. This is Dmitry from Tech Trendsetters, signing off.
🔎 Explore more: