

The Secret to Mastering Distributed Systems: CAP Theorem and Its Extensions
Is the CAP theorem still relevant in today's distributed systems? Explore the CAP role in modern distributed systems, focusing on trade-offs, user impact and service quality

Hello folks, and welcome to another series of Tech Setters where we discuss tech, technologies and computer science in general. Today we talk about distributed systems and CAP theorem in particular. This theorem is a bit like the Swiss Army knife of computer science – incredibly useful, multifaceted, and a must-have in your tech toolkit, whether you're a veteran in the field or just stepping into the arena.
This material is tailored for everyone: from seasoned professionals looking for a quick refresher to eager beginners prepping for their big tech interviews. Our aim is not just to explain but to enlighten, ensuring you walk away not only understanding the CAP theorem but also ready to apply it or explain it, whether in a boardroom or a chat room.
So let's gear up and get off the ground on this educational flight, breaking down complex concepts into bite-sized, easily digestible pieces. Ready?
What's Enough to Know About the CAP Theorem?
… for Interviews at Most Tech Companies?
Let me start with a quick refresher. The CAP theorem, a fundamental principle in distributed computing systems, serves as a cornerstone for understanding how these systems manage data. Initially formulated by computer scientist Eric Brewer, the theorem presents a crucial choice between three properties: Consistency, Availability, and Partition Tolerance.
Eric Brewer introduced this theorem at the Symposium on Principles of Distributed Computing in 2000. Two years later, in 2002, Seth Gilbert and Nancy Lynch from the Massachusetts Institute of Technology (MIT) provided a formal proof of Brewer's hypothesis, thus elevating it to the status of a theorem.
Brewer expressed his intention behind proposing this theorem: he aimed to initiate a discussion within the community regarding the trade-offs in distributed systems. Over the years, he continued to refine and add further nuances to this concept, reflecting the evolving understanding and applications of distributed computing systems.
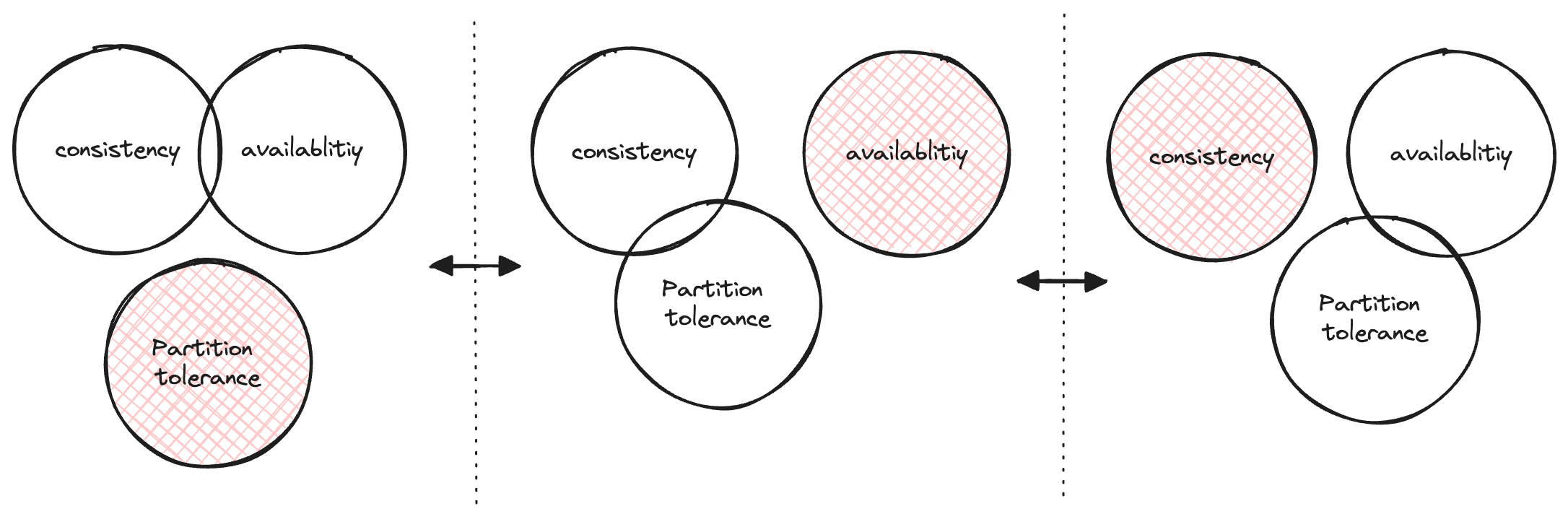
The CAP theorem presents a crucial decision point in the design of distributed systems, emphasizing that only two of the three key properties can be fully achieved at any one time:
Consistency (C): This ensures that every read operation retrieves the most recent write or update in the system, maintaining data uniformity across all nodes;
Availability (A): It guarantees that every request (whether read or write) is successfully processed by each operational node in the system, ensuring that the system is always responsive;
Partition Tolerance (P): This property assures that the system continues to function independently and adequately even when there are interruptions in the communication between nodes, effectively handling network partitions;
In simple terms, the CAP theorem highlights the need to balance these three properties. This leads to three kinds of systems: CA, CP and AP, based on what letter you leave out. It helps system designers understand which two properties are most important for their goals and make choices that best fit their system's needs and limitations.
Here's a look at some of the newer and more popular technologies in the market. This list categorizes them based on the two CAP properties they generally align with, but it's important to note that this categorization is a simplification (continue reading to understand why). In practice, each technology's applicability to a specific set of CAP properties can vary based on its configuration and use case.
CA (Consistency and Availability): PostgresSQL, MySQL, Oracle DBMS, Apache Kafka;
CP (Consistency and Partition Tolerance): MongoDB, Elasticsearch, CockroachDB, Apache HBase;
AP (Availability and Partition Tolerance): ScyllaDB, CouchDB, Redis, Apache Cassandra, Amazon DynamoDB.
Aligning with Use Cases in the Context of the CAP Theorem
While the CAP theorem offers crucial insights for database selection, it's important to recognize the crucial differences in its application between general distributed systems and databases. In distributed systems, the focus is often on the broader architecture and network behavior, considering how different nodes interact, handle failures, or manage data across a network. Let's look at some real-life examples to see how this choice affects different systems:
CA Use Case (Consistency and Availability): In a banking systems where accurate account balance information is crucial. When a network disruption occurs, the system is designed to maintain both consistent data across all accounts and uninterrupted user access. This means, even during network issues, users can access their accounts with the assurance of seeing the most current balance information.
AP Use Case (Availability and Partition Tolerance): An e-commerce site or a popular social network needing to update a vast product catalog or a user’s feed. During the update, waiting for the entire database to reflect these changes before allowing reads would lead to unacceptable downtime. An AP (Availability and Partition Tolerance) database, capable of handling partial updates and providing continuous access to data, is more appropriate in this scenario.
CP Use Case (Consistency and Partition Tolerance): In cloud storage systems, ensuring consistent operations on files across all nodes is vital. Even if a node fails, the system ensures the file is modified everywhere. This can lead to temporary unavailability, but guarantees that once accessible, the system shows no discrepancies on modified file.
But remember:
In practice, many applications are best described in terms of reduced consistency or availability. For example, numerous weakly-consistent distributed systems or databases exist, providing specific, well-defined consistency/availability tradeoffs. These systems also offer the opportunity to adjust these tradeoffs to align with your desired goals. These examples suggest that there is a Weak CAP Principle which we can describe as:
The stronger the guarantees made about any two of strong consistency, high availability, or resilience to partitions, the weaker the guarantees that can be made about the third.
So What's Wrong with Discussions About Consistency
...if you're still preparing for an interview, using the following sections may embarrass your interviewers
Now when we have clarified the basic terminology, we are slowly approaching some friendly criticism, especially given the previous thought about the “weak CAP Principle”. Here comes some ideas to get you thinking.
The author of the CAP theorem, Brewer published a follow-up article in 2012 “CAP twelve years later“ where he emphasizes that the CAP theorem is not to be seen as binary where one of the properties is chosen completely on the behalf of the other. Instead, it is to be seen as a gradual range and modern systems should strive to maximize the combinations of consistency and availability to make sense for its specific use-case.
Why was it necessary for him to write a follow-up to his original work? This elaboration came after a decade of extensive discussions in professional circles, debating and interpreting the theorem's core message.
Problems lays in mathematics. If you want to refer to CAP as a theorem (as opposed to a vague concept in your database’s marketing materials), you have to be precise. Mathematics is precise. The theorem only holds if you use the words with the same meaning as they are used in the original proof. And the proof uses very particular definitions:
Consistency in CAP actually means linearizability, which is a very specific (and very strong) notion of consistency. In particular it has got nothing to do with the C in ACID, even though that C also stands for “consistency”;
Availability in CAP is defined as “every request received by a non-failing node in the system must result in a response”. It’s not sufficient for some node to be able to handle the request: any non-failing node needs to be able to handle it. In addition – the proof still holds if all nodes are down;
Partition Tolerance in CAP basically means that you’re communicating over an asynchronous network that may delay or drop messages. Network disruptions, along with message drops and delays in physical datacenters, are inevitable realities. Therefore, dealing with these challenges is not optional; it's a necessary part of managing data networks.
So the CAP theorem can be considered misleading (but not wrong) for three reasons:
Partitions are rare, and when a system is not partitioned, the system can have both strong consistency and high availability;
Consistency and availability can vary by subsystem or even by operation. The granularity of consistency and availability doest not have to be an entire system;
There are various degrees of consistency and various levels of consistency.
The CAP theorem is too simplistic and too widely misunderstood to be of much use for characterizing systems. Many systems are neither consistent nor available under the CAP theorem’s definitions. Instead, we should use more precise terminology to reason about our trade-offs.
So, what other options are available?
It’s all about Consistency Tradeoffs
Now that we've understood that relying solely on the CAP theorem is not ideal, we should shift our focus to maximizing the combinations of consistency and availability. In 2012, another attempt to extend the CAP theorem emerged.
Daniel Abadi expanded Brewer's theorem by rewriting CAP as PACELC Theorem (pronounced “pass-elk”). It includes two modes of operation: during periods of partitioning and during normal operation:
If there is a partition (P), how does the system trade off availability and consistency (A and C); else (E), when the system is running normally in the absence of partitions, how does the system trade off latency (L) and consistency (C)?

The PACELC theorem essentially shows that systems can either tend towards latency sensitivity or strong consistency.
We have got a new word here – Latency. In the context of distributed systems, Latency refers to the time it takes for a piece of data to travel from one point in the system to another, which is regulated by some level of consistency. Latency, in a sense, represents the degree of availability.
Note that the latency/consistency tradeoff (ELC) only applies to systems that replicate data. Otherwise, the system suffers from availability issues upon any type of failure or overloaded node.
With this interpretation, we can reorganise some databases from our previous example:
PC/EC systems: All fully ACID databases like Oracle or PostgreSQL;
PC/EL systems: Amazon DynamoDB, CockroachDB;
PA/EL systems: Apache Cassandra;
PA/EC systems: MongoDB.
It's important to note that many modern databases (like PostgreSQL), have adjustable configurations and can nowadays be considered for all possible variants.
Combining everything together, the PACELC theorem offers a more comprehensive framework for understanding the trade-offs in consistency within distributed systems and databases. It expands upon the foundational concepts of the CAP theorem by introducing a nuanced perspective that considers both the state of network connectivity and operational scenarios.
But… Can we do better?
A Complementary Perspective of Harvest and Yield
Continuing from the exploration of the PACELC theorem and its implications, we dive deeper by introducing the concepts of Harvest and Yield in distributed systems. These concepts, though less well-known than CAP or PACELC, offer additional insight into the trade-offs made in distributed computing.

The Harvest and Yield model provides another angle to evaluate distributed systems, particularly in scenarios where network partitions or failures occur. This model was proposed by Fox and Brewer, the same Eric Brewer who formulated the CAP theorem (why I am not surprised). It's based on two key metrics:
Harvest: Refers to the completeness of the data returned by the system during a request. A system with a high harvest will return most or all of the requested data, even under failure conditions. Conversely, a lower harvest implies that the system might return partial or incomplete data to maintain other aspects of the system, like response time;
Yield: Represents the probability that the system will be able to complete a request — essentially, its availability. A high-yield system ensures that most requests are successfully handled, even if the completeness of each response (harvest) is reduced.
So in simple words: Yield is the probability of completing a request and Harvest measures the fraction of the data reflected in the response, i.e. the completeness of the answer to the query.
Yield is the common metric and is typically measured in “nines”: “four-nines availability” means a completion probability of 0.9999. For example AWS S3 has amazing numbers in 4 nines availability and 11 nines in durability (99.99% and 99.999999999% respectively).
In practice, good HA systems aim for four or five nines. In the presence of faults there is typically a tradeoff between providing no answer (reducing yield) and providing an imperfect answer (maintaining yield, but reducing harvest). It is important to note that some applications do not tolerate harvest degradation because any deviation from the single well-defined correct behavior renders the result useless.
With this context, also remember the concept of Orthogonal Mechanisms. This principle refers to strategies or features in distributed systems that operate independently but contribute to the system's overall robustness and efficiency. They are “orthogonal” because their functions do not overlap, yet each plays a vital role in ensuring the system's resilience and performance. For example, a typical e-commerce site consists of several parts: a read-only area for user-driven content, a billing section and others. Any of these subsystems, except possibly billing, can fail without rendering the whole service useless.
Bringing all these concepts together, it's clear that while CAP and PACELC focus on the trade-offs between consistency, availability, and latency, Harvest and Yield provide a more user-centric view. They consider the practical implications of these trade-offs on the quality of service experienced by the end-user. This perspective is particularly valuable when designing systems that directly interact with users, where the perceived quality of service can be as important as the technical specifications.
TL;DR
In summary, the world of distributed systems is governed by several pivotal theories and models, each offering unique insights into the trade-offs and decisions involved in system design. The CAP theorem, introduced by Brewer, and its subsequent refinement into the PACELC theorem, provide a fundamental understanding of the balance between consistency, availability, and partition tolerance in distributed systems.
A critical aspect to note is that in the CAP theorem’s trio of Consistency, Availability, and Partition Tolerance, Partition Tolerance is mandatory in distributed systems. You cannot not choose it. This necessity shifts the focus from a choice among the three CAP properties to a more nuanced decision-making process based on system behaviour during failures.
Here, the concepts of Harvest and Yield become particularly relevant. These metrics, focusing on the user's experience, measure the completeness of data (Harvest) and the probability of successfully handling requests (Yield). In practical scenarios, when failures occur, systems must decide whether to sacrifice Harvest (percent of required data actually included in the responses) or Yield (percent of requests answered successfully).
In essence, while CAP and PACELC deal with the technical underpinnings of distributed systems, Harvest and Yield bring in the perspective of service quality and user impact.
The merger of these theories forms a comprehensive framework for system architects and developers. It guides us in making informed decisions that not only meet the technical requirements of a system but also align with the needs and expectations of the end-users. By understanding and applying these principles, one can design robust, efficient, and user-centric distributed systems capable of navigating the complex landscape of modern computing.
If you've read everything up to this point, kudos to you! You've now gained enough wisdom to not only run marathons in the desert but also to potentially embarrass your interviewers with your in-depth knowledge of the CAP theorem and consistency discussions. Seriously though, I appreciate your attention to detail almost as much as Amazon S3 appreciates its nines. Stay safe, stay tuned, and remember – in the vast sea of data, be like S3: resilient, available, and, unlike my attempt at humor, always reliable.
🔍 Explore more