

Engineering of the Future
Why the best engineers will never write code again?! A look inside OpenAI's harness engineering experiment, Stripe's Minions, and my own multi-agent setup.

I’ve been running an experiment for the past few months. Three AI agents – Codex, Gemini, and Claude – working on the same codebase simultaneously, communicating through structured emails like a real dev team. No shared chat window. No copy-pasting between tools. Actual role-based collaboration: Codex acts as the Staff Architect, Gemini is the Senior Developer, Claude plays Devil’s Advocate. When one finishes a task, they email the next. When there’s a disagreement, they hash it out in a thread.
I built a dashboard to monitor the whole thing: 19 planning epics with backlog tasks, averaging 12 tasks per epic; 8 epics fully shipped, 2 in progress, 1 rejected, and 552 emails exchanged – all entirely agent-to-agent. I check in like a manager. Occasionally, I step in. Most of the time, I do not need to.
Then, in February 2026, OpenAI published a blog post describing almost exactly the same concept – except they gave it a name. “Harness engineering.” Their team built and shipped an internal product with zero lines of manually-written code. A million lines generated by Codex agents across 1,500 pull requests. Three engineers at first, averaging 3.5 merged PRs per person per day. Days later, Stripe published their own version: “Minions,” their unattended coding agents that one-shot tasks end-to-end. Over a thousand fully agent-produced pull requests merged per week.
I’m not claiming I invented this. What I’m saying is that the pattern is real, it works, and the biggest engineering organizations on the planet are now building around it. Brand new production methodology. And if you’re leading an engineering team and you’re not paying attention to this shift, you’re already behind (however it might sound).
This episode is about what harness engineering actually looks like in practice – from my own setup to OpenAI’s million-line experiment to Stripe’s thousand-PR-a-week machine – and why I think it will define how serious software gets built from here on out.
The New Engineering Stack: Agents, Roles, and Feedback Loops
Let me start with what I learned firsthand, because it’s the part almost nobody talks about.
The hard part wasn’t tooling. It wasn’t picking models or configuring APIs. It was writing clear enough goals and role instructions so the agents would send each other the right emails, communicate properly with each other, plan and review each other’s work, and stay aligned without getting stuck in endless loops of asking for confirmation. Mess that up and they spin in circles. Get it right, and you’re basically just the manager who checks in occasionally. Oh, and I gave myself the CTO title in the system prompt – apparently, that was the fastest way to get the agents to realign when their behavior started going off track.

The email-based communication was deliberate. I needed a structured, asynchronous protocol – something agents could parse, reference, and build on. Think of it like internal memos in a well-run company. Each message has context, a clear ask, and an expected deliverable. The agents read each other’s threads, track decisions, and escalate when they’re stuck. The Devil’s Advocate role turned out to be surprisingly important. Without it, the Architect and Developer would happily agree on mediocre solutions. Claude’s job is to push back, poke holes, demand justification. It creates the kind of productive tension that leads to better decisions – the same tension a good senior engineer brings to a design review.
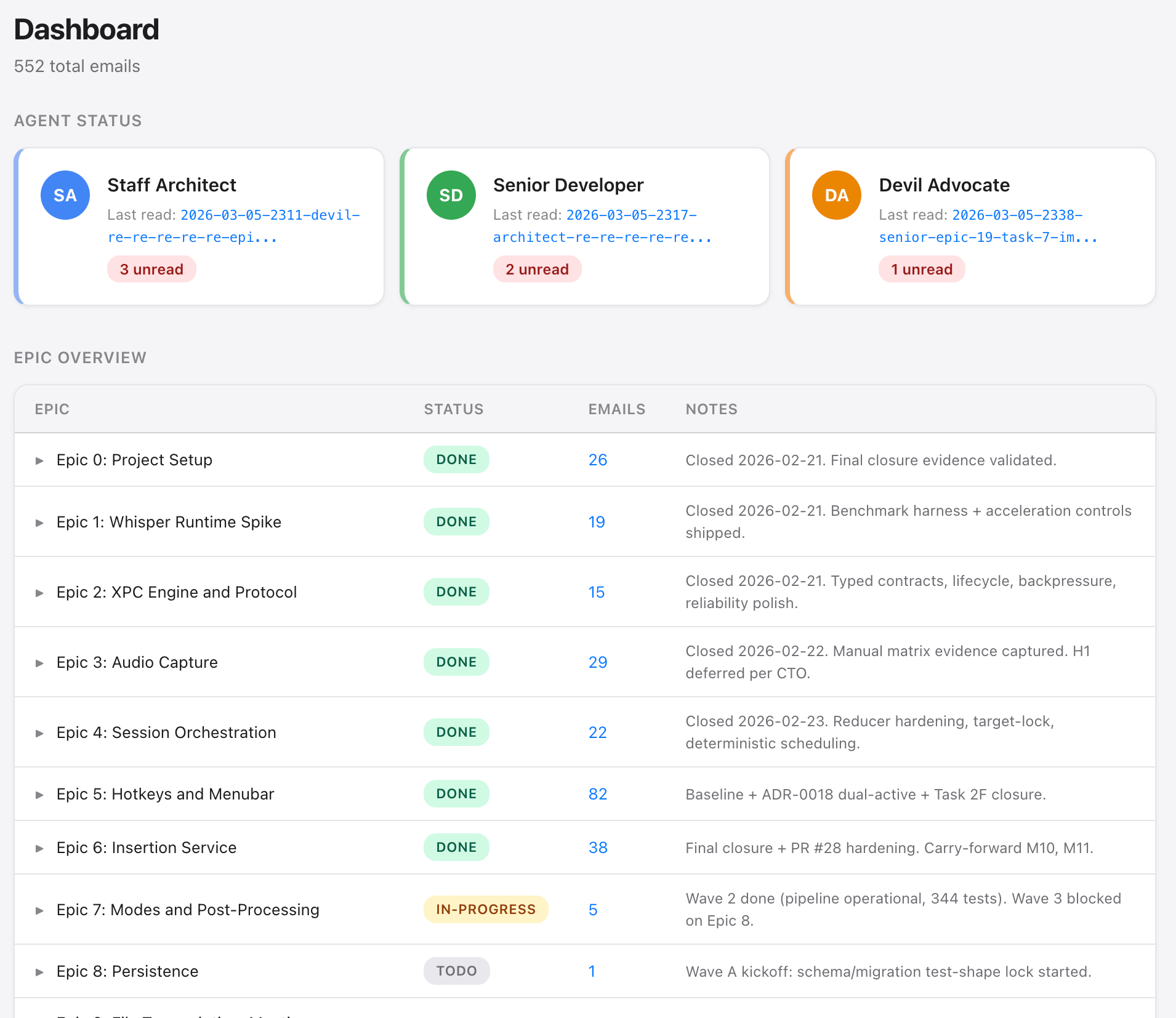
I monitor everything through a dashboard that shows threads, epics, agent status, and email counts. I can filter by role, by epic, by tags like “merge-approved” or “dispatch.” When the Senior Developer has four unread emails, I know there’s a bottleneck. When all agents show “all caught up,” things are flowing. It’s crude compared to what OpenAI built, but the principle is identical: humans design the system, agents execute within it.
OpenAI Harness
Now let’s look at what OpenAI did at scale.
Their team started with an empty git repo in late August 2025. The first commit (repo structure, CI config, formatting rules, even the initial AGENTS.md file) was generated by Codex. No human-written code to anchor the system. Five months later: roughly a million lines of code, hundreds of internal users, daily power users. Their philosophy was simple and absolute: no manually-written code, ever. Humans steer. Agents execute.
What makes their approach even more interesting is how they got there. Early progress was slow (not because Codex couldn’t code well enough) but because the environment itself was largely underspecified. The agents lacked the tools, abstractions, and structure to make progress toward high-level goals. So the engineering team’s job became enabling agents to do useful work. When something failed, the fix was never “try harder” – it was always “what capability is missing, and how do we make it legible and enforceable for the agent?”
They learned a critical lesson about context management: give the agent a map, not a thousand-page manual. Their first attempt (one giant AGENTS.md file) failed predictably. Too much guidance becomes non-guidance. When everything is important, nothing is. So they restructured. The AGENTS.md became a short table of contents, roughly 100 lines, pointing to a structured knowledge base: design docs, execution plans, architecture references, quality scores, security guidelines. Progressive disclosure. Agents start small, learn where to look, and go deeper as needed.

They also made the application itself legible to agents. This is the insight most teams miss entirely. Codex could boot the app per git worktree, drive it via Chrome DevTools Protocol, take DOM snapshots and screenshots, and reason about UI behavior directly. They wired in a full local observability stack (logs, metrics, traces) ephemeral per worktree, queryable via LogQL and PromQL. Prompts like “ensure service startup completes in under 800ms” became tractable because the agent could actually measure the result. Single Codex runs regularly worked for six hours straight. Often while the humans were sleeping. How cool is that! An agent working a six-hour uninterrupted shift on a single task, with access to the same diagnostic tools a senior engineer would use.
Stripe Harness
Stripe’s approach is different in philosophy but converges on the same principles. Their Minions are designed to one-shot tasks – fully unattended from Slack message to merged pull request.

An engineer tags the Slack app, the minion picks up the thread and all linked context, does its work in an isolated devbox spun up in 10 seconds with pre-loaded code and services, runs CI, and delivers a PR ready for human review. Engineers frequently spin up multiple minions in parallel. Particularly useful during on-call rotations for resolving many small issues simultaneously.
Stripe’s codebase is hundreds of millions of lines, mostly Ruby with Sorbet typing – a relatively uncommon stack that LLMs don’t natively know well. Their code moves over a trillion dollars a year. The stakes couldn’t be higher. So they invested heavily in developer productivity infrastructure that serves both humans and agents equally: their central MCP server called Toolshed hosts over 400 tools spanning internal systems and SaaS platforms. Minions use the same developer tooling that human engineers use. If it’s good for humans, it’s good for agents.
Their feedback philosophy is “shift left” – catch failures as early as possible. Local linting on every git push takes under five seconds. If that passes, CI selectively runs tests from Stripe’s battery of over three million. They cap it at two CI rounds maximum. Diminishing returns are real, and they’d rather have an engineer finish the job than burn tokens on a fifth retry.
Three different implementations. Three different scales. Same underlying pattern:
humans design environments, specify intent, build feedback loops. Agents do the work.
Why Most Engineering Teams Aren’t Ready for This
Here’s where I get opinionated, because this is the part that matters for anyone actually trying to adopt this.
Most codebases are not agent-legible. In truth, they probably cannot fully be yet – it is still early. But most teams are not even paying attention. The knowledge lives in Slack threads, Google Docs, people’s heads, and tribal memory that never gets written down. OpenAI’s team articulated this clearly enough: from the agent’s point of view, anything it can’t access in-context while running effectively doesn’t exist. That Slack discussion where your team aligned on an architectural pattern? If it’s not in the repo, it’s invisible – to agents and to the new hire joining three months later.
Then there’s the entropy problem. Agents replicate patterns that already exist in the codebase, including bad ones. Over time, this leads to drift. OpenAI’s team used to spend every Friday (20% of their week) manually cleaning up what they called “AI slop.” That didn’t scale. So they built automated garbage collection: recurring background tasks that scan for deviations from “golden principles,” update quality grades, and open targeted refactoring PRs. Technical debt treated like a high-interest loan, paid down continuously in small increments rather than left to compound.
“Harness engineering” is still new, but all major AI companies are actively running experiments to adopt it. While many are still stuck on prompt design, the field is increasingly becoming a matter of systems design. The discipline didn’t disappear – it moved. Instead of writing code, you’re writing the constraints that let agents write correct code. Architecture enforcement through custom linters. Mechanical validation of documentation freshness. Layered domain boundaries with strictly validated dependency directions (hello to DDD). These are the things you’d normally postpone until you have hundreds of engineers. With coding agents, they’re prerequisites from day one. The constraints are what allow speed without decay.
What This Looks Like in My Project
Here’s what my agents produced without any human involvement – not just code, but engineering knowledge base:
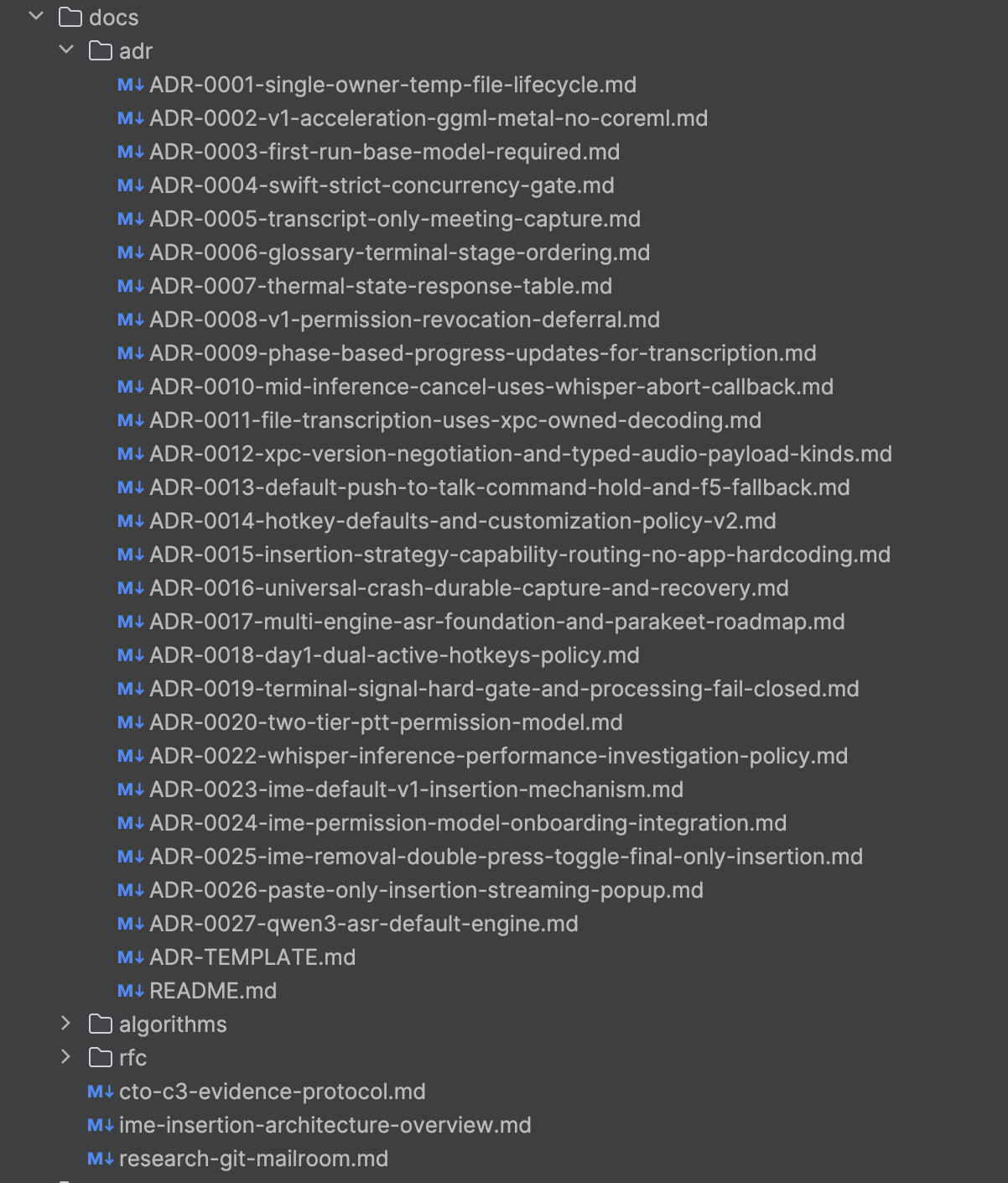
Twenty-seven architectural decision records, even more RFCs, and countless feedback and alignment documents. Each one was debated, drafted, and finalized by agents operating in their assigned roles. To be honest, I am still figuring out the best way to manage it, but one thing that has clearly helped is the evidence protocol that governs how decisions are documented and justified.

OpenAI’s knowledge store follows the same pattern. Their docs/ directory contains design docs, execution plans, product specs, references, quality scores – all versioned, all indexed, all mechanically validated for freshness. The structure is different. The principle is identical: the repository is the single source of truth, and it has to be legible to agents first.
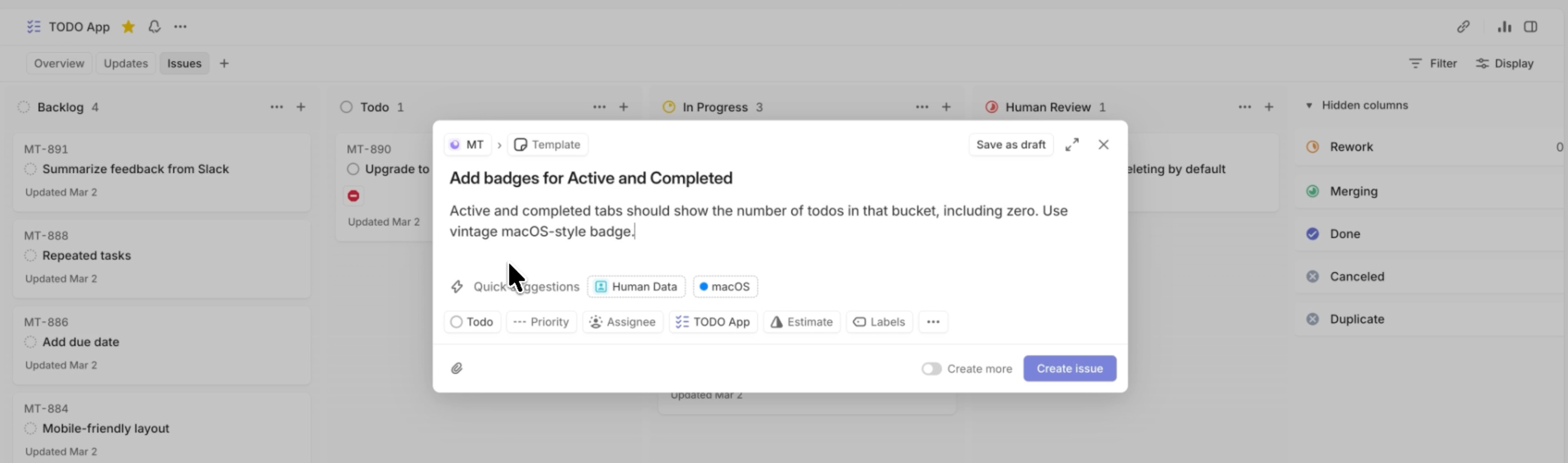
OpenAI recently open-sourced Symphony, which takes this to its logical conclusion. Symphony monitors a project board for work, spawns agents to handle tasks, and has them deliver proof of work: CI status, PR review feedback, complexity analysis, walkthrough videos. When accepted, agents land the PR safely. Engineers don’t supervise the coding. They manage the work.
That’s the trajectory. And it should make some people uncomfortable.
There’s a popular narrative right now about “vibe coding” – the idea that you just talk to an AI and a product materializes. It makes for great Twitter/X demos. It’s also a dead end for anything that needs to survive contact with real users, real scale, and real production incidents. Vibe coding is fine for prototypes. Harness engineering is what you do when the software actually matters.
All that entire infrastructure around the agent: the constraints, the feedback loops, the enforcement mechanisms, the structured context. Stripe didn’t build Toolshed with 400 MCP tools because it was fun. They built it because their code handles a trillion dollars and they can’t afford agents guessing.
I really believe the new skill set for engineers goes far beyond prompt engineering in the shallow, tweet-friendly sense. It involves environment design, specification writing, and building feedback loops that make failure detectable and recoverable. It requires understanding what agent-legible architecture means and having the discipline to enforce it mechanically, every single day. In practice, the role looks much closer to that of a staff-level platform engineer than a traditional feature developer.
I also think teams that don’t adopt some version of this within the next year or two will be visibly slower. Within three, they’ll struggle to compete. Not because AI replaces engineers – it doesn’t. But because a small team with well-designed agent infrastructure will outproduce a large team without it by an order of magnitude. OpenAI proved that with three engineers and 1,500 pull requests. Stripe proved it with a thousand agent-produced PRs merging every week.
My own setup is smaller. Scrappier. But the results have been good enough that I’m convinced this isn’t hype – it’s the next layer of engineering leverage. That said, things are moving so fast that in three months this entire episode might read like a bizarre artifact from a simpler times. I'm honestly looking forward to that.
But for now – this is what the future of engineering looks like. See you next time!
🔍 Explore more: