

Understanding Retrieval-Augmented Generation (RAG): Is This the End of Traditional Information Retrieval?
Learn how to use RAG to augment your business intelligence tools. Explore the evolution of RAG, from its basic principles to advanced techniques

Welcome back, my fellow tech enthusiasts! You’re here and that means it's time for another episode of Tech Trendsetters. While in 2023, we feared that Generative AI might ruin the humanity, in 2024, we're dreaming of harnessing its potential and scaling it down for practical, down-to-earth use cases.
Today, we will try understand the concept of RAG – Retrieval-Augmented Generation. Let's be honest here: we've all had to deal with managers, directors, and CXOs who come up with the "amazing" idea of interacting with company data and documents. So, is it really an easy task to do nowadays? Well, the answer is: yes and no.
Most of you are familiar with the basics of RAG. But the landscape is shifting fast, and if you think you know everything about RAG, think again.
In the mere months since the RAG concept first appeared, we've seen some game-changing developments. From GraphRAG to FLARE, from massive context windows to the rise of knowledge graphs – the RAG ecosystem is exploding with innovation.
These aren't just incremental improvements. We're talking about fundamental shifts in how RAG systems operate, learn, and interact with data. And the implications? They're big – not just for AI development, but for how businesses operate, how we access information, and even how we approach knowledge itself.
In this episode, we'll cut through the hype and get to the heart of these advancements. We'll explore how to address RAG's previous limitations and where they might still fall short. We'll look at real-world applications that are pushing the boundaries of what's possible.
And of course, we'll peer into the future. With the pace of change we're seeing, what can we expect in the next 6 months? The next year? How should businesses be preparing?
So, whether you're an AI engineer looking to stay ahead of the curve, a business leader trying to leverage these technologies, or just a tech enthusiast eager to understand where we're headed – this episode is for you. Let's start in and unravel the evolving world of RAG.
Retrieval-Augmented Generation (RAG) – What It Is and Why It Matters
So what exactly is RAG, and why has it become such an important development in the field of artificial intelligence?
The term "Retrieval-Augmented Generation" was coined by Patrick Lewis in mid-2020. But it's in the era of Large Language Models (LLMs) that RAG has truly come into its own. In its simplest form, RAG is about giving AI models access to external knowledge sources, allowing them to retrieve relevant information on the fly.
Method combines the power of LLMs with external knowledge retrieval. The basic idea is simple yet powerful: instead of relying solely on the knowledge baked into a pre-trained model, RAG systems can pull relevant information from external sources to inform their responses.
Here's how RAG typically works:
A user posts a query or input to the system;
The system searches through a vector database or other knowledge store for relevant information;
It retrieves the most suitable data related to the query;
The LLM then uses this retrieved information to generate a response;
This approach addresses one of the key limitations of traditional LLMs: their inability to access up-to-date or domain-specific information beyond their training data. With RAG, models can tap into vast repositories of knowledge, making them more versatile and accurate. Sounds just perfect, doesn’t it?
The significance of RAG in the tech industry is underscored by its recent promotion on the ThoughtWorks Technology Radar. In April 2024, ThoughtWorks moved RAG from the "Trial" to the "Adopt" category, signaling its readiness for widespread implementation. This shift reflects the growing confidence in RAG's effectiveness and its successful application in various real-life projects.
There are at least several key aspects of RAG:
RAG significantly enhances the output of LLMs by providing relevant and trustworthy context, overall improving response quality;
By grounding responses in retrieved information, RAG results in reduced hallucinations and helps minimize the generation of false or irrelevant content, which is particularly important when large frontier models are not used;
RAG allows for versatility in document types as the approach works with various document formats, including HTML, PDF, tables and others;
RAG is an approach, not a concrete technology. It offers database flexibility and can be implemented using various vector databases or efficient document search systems like pgvector, Qdrant, or Elasticsearch Relevance Engine;
The significance of RAG becomes clear when we consider its practical applications. For instance, in a corporate setting, RAG can enable AI systems to access and utilize company-specific documents, policies, and data. This means chatbots or AI assistants can provide accurate, context-aware responses about company procedures, product details, or customer information – something that would be impossible with a standard LLM.
Moreover, RAG systems can be updated with new information without requiring a full retraining of the underlying language model. This dynamic nature makes RAG particularly valuable in fast-changing environments where information needs to be current and accurate.
The development of RAG represents a shift from static, pre-trained models to more flexible, context-aware AI systems. It bridges the gap between the generative capabilities of LLMs and the need for factual, retrievable information.
However, it's important to note that RAG is not without challenges. The quality of responses heavily depends on the effectiveness of the retrieval process and the quality of the knowledge base. Issues like irrelevant retrievals or "hallucinations" (where the model generates false information) can still occur.
Under the Hood: From Naive to Advanced RAG

The RAG landscape takes us through three distinct paradigms:
Naive RAG: This is the simplest form, involving a straightforward process of indexing, retrieval, and generation. It's like giving a student a textbook and asking them to find the relevant information;
Advanced RAG: This paradigm addresses the limitations of Naive RAG by introducing sophisticated techniques like query rewriting, chunk reranking, and prompt summarization. It's akin to teaching the student not just to find information, but to critically evaluate and synthesize it;
Modular RAG: The most flexible approach, Modular RAG allows for the substitution or rearrangement of different components within the RAG process. It's like giving our student a whole toolkit of research methods and letting them choose the best tools for each task.
The Core Components – Naive RAG Approach
At its heart, RAG consists of three main concepts:
The Retriever – the part that searches through the knowledge base to find relevant information;
The Generator – the language model that takes the retrieved information and crafts a response;
The Augmentation Process – this is where the magic happens – the seamless integration of retrieved information into the generation process.
And consists of three main components:
A vector database for storing and retrieving information;
An embedding model for converting text into vector representations;
A large language model (LLM) for generating responses;
Now, let's take a look at what's known as "Naive RAG" – the simplest form of Retrieval-Augmented Generation. Here's how these components work together in a typical RAG pipeline:
Data Ingestion and Indexing
The first step is to prepare your knowledge base. This involves taking your company's documents, breaking them down into smaller chunks, and storing them in a vector database. Here's the basic process:
Text Chunking: Documents are split into smaller, manageable pieces. This is crucial because most embedding models have input size limitations.
Embedding Generation: Each chunk is then passed through an embedding model. This converts the text into a high-dimensional vector representation that captures its semantic meaning. Popular choices for embedding models include:
Sentence transformers based on BERT
OpenAI's text embeddings
More recent models like BGE (BAAI General Embedding)
Vector Storage: These embeddings are stored in a vector database along with their corresponding text chunks. Popular choices for vector databases include:
Qdrant
Pinecone
Chroma
Weaviate
Milvus
FAISS (a framework from Facebook AI Research)
Some traditional databases have also started offering vector capabilities:
pgvector for PostgreSQL
Atlas Vector Search for MongoDB
Query Processing

When a user asks a question, the RAG system processes it as follows:
Query Embedding – The user's question is converted into a vector using the same embedding model used for indexing.
Similarity Search – This query vector is used to search the vector database for the most similar chunks. This is typically done using cosine similarity or other distance metrics.
Retrieval – The system retrieves the top K most similar chunks. The value of K is a hyperparameter that can be tuned based on the specific use case.
Context Preparation
The retrieved chunks need to be formatted into a prompt for the LLM. A basic prompt template might look like this, where context variable has all chunks retrieved from the previous step:
Use the following pieces of context to answer the question at the end.
Context:
{{context}}
Question: {{question}}
Answer:Response Generation
Finally, this prompt is sent to the LLM (such as Gemini or Llama) for generation. The LLM uses the provided context to formulate a response to the user's question.
At this step LLM combines the retrieved information with its pre-trained knowledge to produce a coherent and relevant answer. The selection of the LLM for response generation is a critical decision that can significantly impact the performance, capabilities, and cost-effectiveness of a RAG system.
Limitations of Naive RAG approach
While this approach is powerful, it has several limitations:
Query Understanding – Naive RAG takes user queries at face value, which can be problematic given the wide variety of ways users might phrase their questions;
Retrieval Quality – The effectiveness heavily depends on the quality of retrieved information. Poor retrieval can lead to irrelevant or misleading responses;
Context Integration – It doesn't account for the relevance of retrieved documents beyond vector similarity, nor does it handle complex queries that might require multi-step reasoning;
Consistency Issues – It can struggle with maintaining consistency across multiple turns of conversation;
Handling Specific Challenges – Naive RAG doesn't have built-in mechanisms for dealing with hallucinations or managing long contexts that exceed the LLM's context window.
Advanced RAG: Addressing the Challenges
To overcome these limitations, researchers and developers have introduced several advanced techniques:
Enhanced Query Processing
Query Rewriting
Using LLMs to rephrase or expand the original question to capture the user's intent more accurately. Alternatively use LLMs to generate multiple versions of the user's question. This approach helps capture different aspects of the query that might be missed with a single formulation.RAG Fusion
Generating multiple versions of the user's question, performing separate searches for each, and then combining the results. Combine and re-rank the results using more sophisticated models like Cross Encoders. This method improves the chances of retrieving relevant information, especially for complex queries.Classification
Classifying incoming queries (e.g., as questions, complaints, requests) to route them more effectively. Implementing a classification system to categorize queries by department (e.g., accounting, production, HR), urgency level, or query type (question, complaint, request). Then use this classification to route queries more effectively or adjust the response strategy.
Improved Retrieval Techniques
Hybrid Search:
Combining dense (vector-based) and sparse (keyword-based) retrieval methods. This approach leverages both semantic understanding and exact matching capabilities.Ensemble Retrievers
Using multiple retrieval methods and combining their results. Example: Combine results from vector search, keyword search, and potentially even external search engines. Aggregate results using methods like reciprocal rank fusion.Iterative Retrieval
Performing multiple rounds of retrieval, refining the search based on initial results. This is a variant of multi-hop or recursive retrieval for complex queries. First retrieve smaller document chunks to capture key semantic meanings, then in later stages, provide larger chunks with more contextual information to the language model.
Context Optimization
Advanced Chunking Strategies
Using semantic segmentation or title-based segmentation to preserve context more effectively. Implement sliding window fragmentation with overlapping chunks. Adjust chunk size based on the specific embedding model used. For instance, BERT-based models work well with chunks up to 512 tokens. Then use semantic segmentation or title-based segmentation to preserve context more effectively.Metadata Enrichment
Adding metadata to chunks to help in filtering and ranking results. Metadata, such as source, date, category, and relationships between fragments has a significant impact on the performance and relevance of results.
Sophisticated Ranking and Merging
Re-ranking
Using more computationally expensive models (like Cross Encoders) to re-rank initial retrieval results. Implement custom relevance scoring algorithms that consider factors beyond vector similarity, such as document freshness, source reliability, and contextual relevance.Relevance Scoring
Custom relevance scoring algorithms are designed to consider multiple dimensions of relevance, making the retrieval process more robust and tailored to the user's needs. Custom scoring algorithms that take into account multiple factors:Vector similarity
Keyword matching
Metadata relevance
Document recency
Source authority
Advanced Generation Techniques
Prompt Engineering
Carefully crafting prompts that guide the LLM in using the retrieved information effectively. Include system instructions like "use only the provided information" to guide the LLM's behavior. Also refer the official model documentation for more specific details and usage nuances.Multi-step Reasoning
Breaking down complex queries into multiple steps, potentially with intermediate retrievals. Implement techniques like Chain-of-Thought prompting or step-by-step reasoning.
Handling Long Contexts
Implement techniques to handle scenarios where relevant information exceeds the LLM's context window.
Use methods like recursive summarization or hierarchical retrieval.
Example: LangChain's
ConversationSummaryMemoryclass for summarizing long conversations.
Knowledge Graph Integration (GraphRAG)
Implement a knowledge graph alongside the vector database to capture structural relationships between entities.
Use the knowledge graph for enhancing retrieval by understanding the context and relationships between pieces of information.
Example: If a user asks about a company's phone number, the knowledge graph can help identify that this information is stored under "Company Information" even if not explicitly stated.
Self-Reflective RAG (Self-RAG)
Fine-tune the LLM to generate self-reflection tokens:
Retrieve: Determines whether to retrieve chunks for the prompt.
ISREL: Determines if a chunk is relevant to the prompt.
ISSUP: Checks if the LLM's response is supported by the chunk.
ISUSE: Assesses the usefulness of the LLM's response to each chunk.
Use these tokens to guide the retrieval and generation process, allowing the system to be more self-aware and adaptive.
FLARE (Forward-Looking Active Retrieval Augmented Generation)
FLARE introduces a dynamic retrieval process where the language model actively decides when and what to retrieve based on its uncertainty during the generation process.
Unlike traditional RAG that retrieves information only once at the beginning, FLARE performs multiple retrievals throughout the generation process.
By continuously gathering relevant information, FLARE allows the model to generate more accurate and contextually enriched responses, particularly for long-form content.
Hypothetical Document Embeddings (HyDE)
Instead of using the user's question directly for vector search, use the LLM to generate a hypothetical answer.
Use this generated answer to search the vector database for similar real answers.
This technique can be particularly useful for abstract or complex queries where direct matching might fail.
Evaluation and Refinement
Using Another LLM for Assessment
Logit Analysis: Instead of generating text, an LLM can return logits, which are raw scores indicating the likelihood of each token in the vocabulary following the current sequence.
By examining the distribution of these logits, you can determine the model's confidence in its response. High probabilities indicate high confidence, while low probabilities may suggest potential hallucinations.
Calculating uncertainty at the token level helps in identifying parts of the response where the model is less certain, indicating areas that might need refinement or review.
Automated Evaluation Metrics
BLEU (Bilingual Evaluation Understudy): Measures how many n-grams in the generated text match the n-grams in the reference text. Higher scores indicate better alignment with expected responses.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Evaluates the overlap of n-grams between the generated text and reference text. It's particularly useful for summarization tasks.
METEOR (Metric for Evaluation of Translation with Explicit ORdering): Considers synonyms and stemming, providing a more nuanced evaluation compared to BLEU.
Feedback Loops
Incorporating user feedback to continuously improve the system's performance. Use this feedback to refine retrieval strategies, prompt designs, and even to update the knowledge base.
These advanced techniques transform the simple Naive RAG approach into a more sophisticated system capable of handling complex queries, maintaining consistency, and producing more accurate and relevant responses.
It's important to note that these are not all the techniques available, as RAG, LLMs and Vector databases continue to actively develop. But understanding these advancements highlights that a good production-grade system requires a little bit more than just a naive RAG implementation.
Limitations of Retrieval-Augmented Generation (RAG)
While the advancements and enhancements in Retrieval-Augmented Generation (RAG) are impressive, it’s important to understand that any RAG system is not without its limitations. These limitations can significantly impact the effectiveness and reliability of RAG systems, especially in real-world applications. In this section, we'll explore some of the critical limitations of RAG and explore how they can affect its performance.
Dependence on Quality of Retrievals
One of the fundamental limitations of RAG is its heavy reliance on the quality of the retrieved documents. If the retrieval component fails to fetch relevant and accurate documents, the generated response will likely be flawed. This issue can arise due to:
Ambiguous Queries: User queries can sometimes be vague or ambiguous, leading to the retrieval of irrelevant documents.
Poor Indexing: If the documents in the knowledge base are not properly indexed and structured, it can result in suboptimal retrievals.
Outdated Information: In dynamic environments, information can quickly become outdated. If the knowledge base is not regularly updated, the system may provide obsolete answers.
Scalability Challenges
As the volume of documents increases, maintaining high retrieval accuracy becomes challenging. Large-scale document repositories require more sophisticated indexing and retrieval mechanisms to ensure performance does not degrade. The following factors contribute to scalability challenges:
Increased Latency: As the dataset grows, retrieval processes can become slower, affecting the overall response time of the system.
Resource Intensive: Large-scale RAG systems demand significant computational resources for indexing, storage, and retrieval operations.
Contextual Relevance and Integration
Ensuring the retrieved documents are contextually relevant to the user query and integrating them effectively into the generation process is complex. Issues that arise include:
Context Drift: When the retrieved documents are not closely related to the query, the generated response can drift off-topic.
Context Window Limitations: LLMs have a limited context window. If the relevant information exceeds this window, critical details might be omitted, leading to incomplete or incorrect responses.
Handling Complex Queries
RAG systems often struggle with complex, multi-faceted queries that require advanced reasoning and synthesis. This limitation manifests in several ways:
Multi-Step Reasoning: RAG systems are generally less effective at handling queries that need multi-step reasoning or logical inference.
Synthesis of Information: Combining information from multiple documents to generate a coherent and accurate response can be challenging, especially if the documents have conflicting information.
Hallucinations and Misleading Information
Despite efforts to ground responses in retrieved documents, RAG systems can still suffer from hallucinations – where the model generates information that is not present in the retrieved documents. This can occur due to:
Overconfidence in LLMs: LLMs might generate plausible-sounding but incorrect responses if they are overly confident in their internal knowledge.
Mismatched Context: If the context provided by the retrieved documents is not well-matched to the query, the LLM might fill gaps with incorrect information.
Maintenance and Updating
Keeping the RAG system's knowledge base updated with the latest information is essential but challenging. Continuous maintenance is required to:
Incorporate New Information: Regular updates are needed to include new documents and remove outdated ones.
Monitor Performance: Ongoing monitoring and fine-tuning of both retrieval and generation components are necessary to maintain system performance.
Security and Privacy Concerns
Incorporating external knowledge sources into RAG systems can introduce security and privacy risks. Sensitive information might be inadvertently retrieved and included in responses, leading to potential data breaches. Key considerations here:
Access Control: Implementing strict access controls to ensure only authorized documents are retrieved.
Data Sanitization: Ensuring that sensitive information is properly sanitized before being included in the knowledge base. However, this can conflict with the system's purpose, where sometimes privacy must be compromised to enhance features.
When to Choose RAG Over Other Methods?
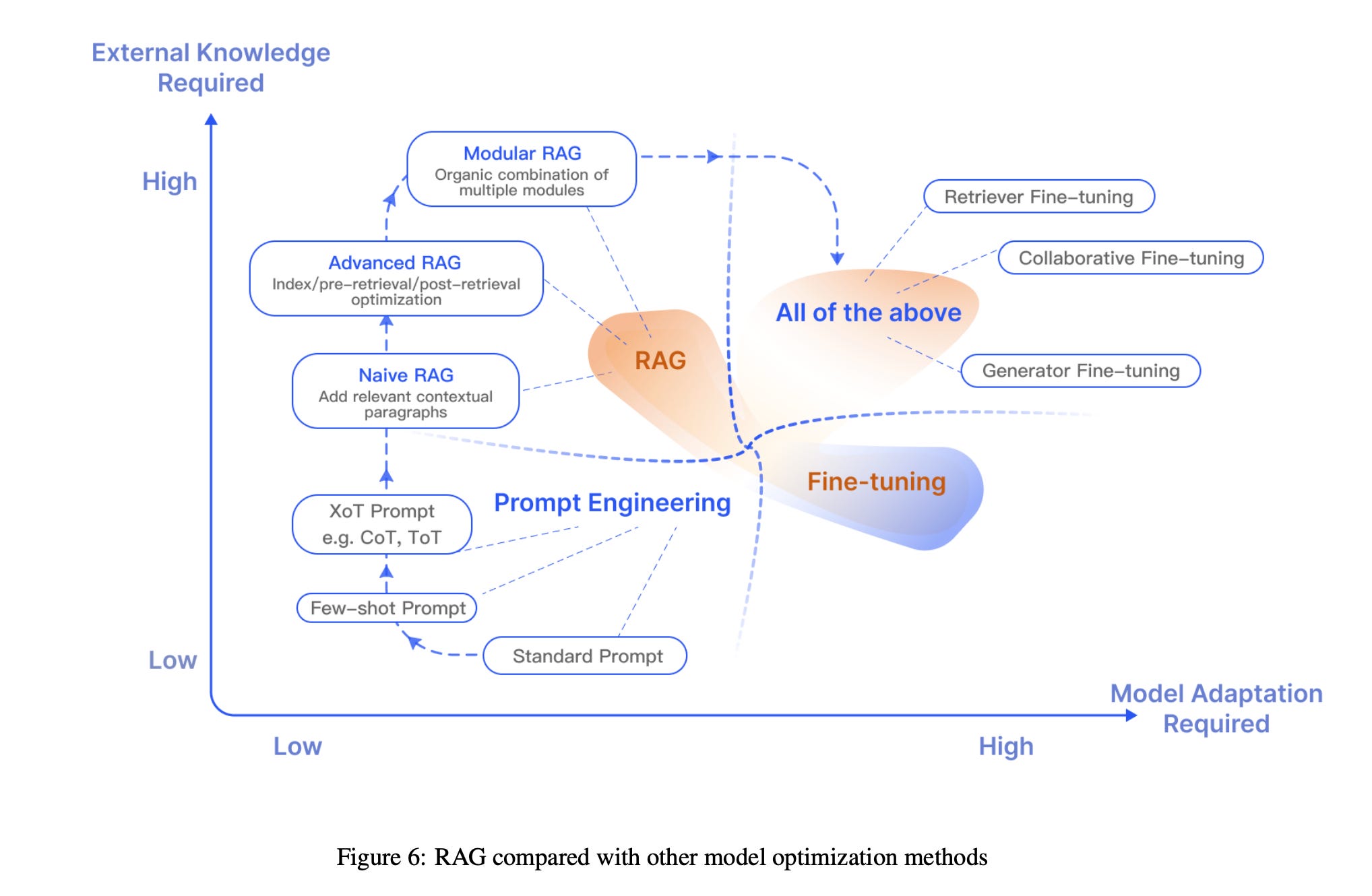
Retrieval-Augmented Generation (RAG) presents a compelling approach for enhancing the capabilities of Large Language Models (LLMs) by integrating external knowledge sources. However, the decision to use RAG over other methods depends on various factors, including the specific needs of the application, the nature of the data, and the desired outcomes.
Dynamic and Up-to-Date Information Needs
One of the primary strengths of RAG is its ability to access and utilize up-to-date information from external sources. This makes it highly suitable for applications where current data is crucial:
When users need information on recent events or developments, RAG can retrieve the latest articles and data to provide accurate and timely responses.
For industries that are heavily regulated and subject to frequent changes in laws and guidelines, RAG can ensure the information provided is always current and compliant.
Domain-Specific Knowledge Integration
RAG excels in scenarios requiring access to specialized or domain-specific knowledge that may not be fully covered in the pre-trained model's dataset:
In fields such as healthcare and law, where accuracy and specificity are critical, RAG can retrieve authoritative documents and guidelines to support the generated content.
For technical documentation or customer support, RAG can pull relevant excerpts from vast repositories of manuals, FAQs, and knowledge bases.
Cost-Effectiveness and Flexibility
Compared to fine-tuning large models, RAG can be a more cost-effective solution:
Organizations with limited computational resources or budgets can implement RAG to improve model performance without the need for extensive fine-tuning.
RAG allows for easy updates to the knowledge base without retraining the entire model, making it ideal for environments where information changes rapidly.
Enhanced Query Understanding and Response Generation
Advanced RAG systems improve the understanding of user queries and the relevance of responses:
For applications involving complex or nuanced user queries, RAG can better interpret and respond by pulling relevant context from multiple documents.
In personalized applications, such as tailored recommendations or custom assistance, RAG can leverage user-specific data to enhance the relevance and quality of responses.
While RAG offers numerous advantages, it’s important not to be mistaken – implementing this technology might not be as straightforward as expected. There is always the chance that the outcomes may not align perfectly with the specific needs of your particular problem. Therefore, understanding the business needs, the data, and the technology is crucial for the success.
Wrapping It Up: Where RAG Stands and Where It's Headed

We've covered a lot of ground in our exploration of Retrieval-Augmented Generation. From its basic principles to cutting-edge techniques, RAG has come a long way in a short time. It's changing how we think about AI and information retrieval.
But let's face it – tech never stands still. Recent developments in Large Language Models are shaking things up:
Bigger Context Windows: Models like Claude can now handle 200,000+ tokens, while Gemini is pushing for a whopping 10 million. This means entire datasets might fit in one go. We're already seeing this impact in fields like financial analysis, where some tasks no longer need separate retrieval steps, nor vector databases.
Cheaper Tokens: As token costs drop, the financial argument for complex RAG systems is changing. For many jobs, it's becoming more practical to just feed more data straight into the model.
Context Caching: Yes, good old caching. With models like Gemini 1.5 Flash sporting massive context windows, context caching is becoming another game-changer. By caching the context, you're cutting down on costs and speeding things up when you're hitting the same large dataset with multiple shorter requests. It's like giving your AI a memory boost.
Now, it's worth noting that not everyone's singing RAG's praises. Some skeptics argue that RAG is just glorified prompt engineering – a fancy way of dressing up what's essentially still about crafting the right input. It's a perspective that reminds us to stay critical and not get caught up in the hype.
Does this mean RAG is on its way out? Not so fast.
These advancements bring their own set of challenges:
As AI gets smarter, controlling who can access what information becomes crucial. RAG systems, by separating retrieval from generation, offer control that pure LLMs can't match yet;
For industries that need very specific, constantly updated domain information, RAG is still the go-to solution for accuracy and flexibility;
As we push AI further, we need to stay on top of the ethical implications and legal regulations. Well-designed RAG systems can help ensure sensitive data is handled properly and AI responses are backed by solid sources;
Looking ahead, it's clear that no single approach will dominate. The future of AI lies in smartly combining different technologies. Whether it's RAG, massive context windows, fine-tuning, context caching, function calling or something we haven't even thought of yet, the key is understanding what each approach does best and using it to solve real business-problems.
Thank you for joining me on this exploration of Retrieval-Augmented Generation. I always like to stay positive – today's challenges drive tomorrow's breakthroughs, pushing us towards AI systems that are not just more powerful, but also more accessible, making everyone's lives easier.
Keep an eye on Tech Trendsetters for more insights on how AI is reshaping our world. Until next time!
🔎 Explore more: