

The Evolution of Application Architecture: Crafting Code that Stands the Test of Time
Explore the journey from three-tier to clean architecture. Learn how modern design principles create flexible, maintainable systems that evolve with your business needs and save costs long-term

Hello, fellow tech visionaries! Welcome to another insightful episode of Tech Trendsetters, where we dive deep into technology, science, and artificial intelligence. Today, we're back to exploring the engineering side of things, specifically focusing on the foundation of any modern system – application architecture (but please, don't confuse this with system architecture)!
As you know, in the world of software, architecture is the invisible foundation that can make or break your entire business. And trust me, after today's journey, you'll never look at your favorite apps the same way again.
The Architect's Dilemma
My journey into the world of application architecture began with a series of rescue missions. I was often called upon to salvage projects that were struggling or had completely stalled. Truth to be told, in some cases, I had been part of the problem. What all these projects had in common was a lack of clarity and a tangled mess of code that defied understanding.
One particular project stands out in my memory. It was a complex system with a “interesting” structure. I spent days trying to decipher its inner workings, searching for the inputs, outputs, and integrations of each module and service. It felt like I was an archaeologist, carefully excavating remains of an ancient civilization, trying to piece together how everything once functioned. I have to confess, this was the moment when the frustrating experience highlighted even more the importance of a well-defined architecture.
As I started to read more and more about application architecture afterwards, I realized that many of the popular architectural styles were presented in a highly abstract manner. Beautiful diagrams adorned the pages of articles and presentations, but they offered little guidance on how to implement these concepts in real-world code.
There was an obvious gap between the theoretical world of architecture and the practical realities of software development. Many developers, especially those with less experience, were unfamiliar with the different architectural styles beyond the basic three-tier model. They lacked the understanding of why these architectures were designed the way they were, and how they could be applied to solve real-world problems.
This realization sparked this episode, where we will go through the evolution of application architectures, from its humble beginnings to the cutting-edge designs of today. Along the way, we'll uncover the hidden pitfalls that have tripped up even the most brilliant developers and reveal the secrets to crafting software that stands the test of time.
The Three-Tier Architecture vs The Three-Layer Architecture
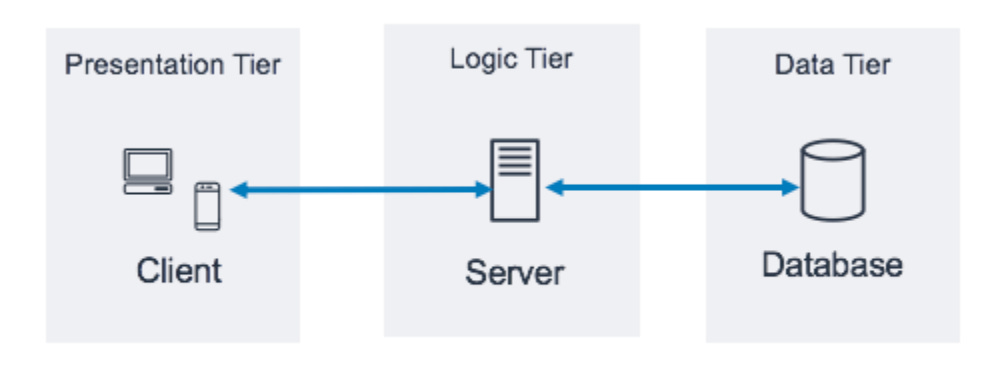
The three-tier architecture emerged in the late 1980s and gained widespread popularity in the mid-1990s. It provided a simple model for organizing software systems, dividing them into three distinct layers: the presentation layer, the business logic layer, and the data access layer.
This model became the standard for many applications, with developers familiar with the concept of controller classes, service classes, and repository classes. Interestingly, even today, not everyone fully understood the purpose of each layer, particularly the importance of layer isolation and domain logic.
Tier versus layer
In discussions surrounding three-tier architecture, the terms layer and tier are often used interchangeably, but this is a common mistake.
They aren't the same. A “layer” refers to a functional division of the software, but a “tier” refers to a functional division of the software that runs on infrastructure separate from the other divisions. The Contacts app on your phone, for example, is a three-layer application, but a single-tier application, because all three layers run on your phone.
The difference is important because layers can't offer the same benefits as tiers.
Understanding the Three-Layer Architecture
While the three-tier architecture focuses on the physical separation of components across different servers or machines, the three-layer architecture is more concerned with the logical separation of concerns within the software itself. This approach allows developers to organize and manage code more effectively, ensuring that different aspects of the application remain modular and maintainable.
There is plenty of existing material on the internet about the three-layer architecture, so I won’t retell it all here. Just remember that the three layers are:
The Presentation Layer (UI);
The Business Logic Layer (Service);
The Data Access Layer (Repositories/DAOs);
And here's where it gets interesting. As applications grew more complex, developers started to realize something was missing. They had these giant "god classes" that did everything from making coffee to solving world peace. Okay, maybe not that extreme, but you get the idea.
The three-layer architecture is absolutely suitable for small projects, especially those with simple logic. However, as the project grows in complexity, the limitations of this architecture quickly become evident.
The Domain-Driven Design Revolution
Despite the clear benefits of the three-tier architecture, it wasn't until 2003 that a visionary named Eric Evans stepped in and said, We need to rethink how we structure our software. His book on Domain-Driven Design (DDD) offered a fresh perspective on organizing code. Today, this book is considered the holy grail for anyone deeply involved in software architecture, teaching us how to declutter our codebases and ensure everything is in its proper place.
Rethinking Software Structure
In fact, DDD is far more than just another architectural style. It's a whole mindset, a philosophy that fundamentally changes how we approach building software.
The concept of domain-driven design, popularized by Eric Evans, introduced a new perspective on application architecture. It emphasized the importance of separating business logic into distinct domains, rather than having a single "god class" that handled everything.
The concept of bounded contexts, aggregates, and entities, providing a framework for organizing complex business logic. It encouraged developers to model software closely to the business domain, improving communication between technical and non-technical stakeholders.
Based on Layered Architecture

While DDD is often misunderstood as a complete departure from layered architecture, it's crucial to understand that it actually builds upon and refines the layered approach.
A common pitfall in software development: the tendency to mix concerns within code. As Eric Evans states, "In an object-oriented program, UI, database, and other support code often gets written directly into the business objects. Additional business logic is embedded in the behavior of UI widgets and database scripts. This happens because it is the easiest way to make things work, in the short run."
The problem with this approach is that it makes the codebase difficult to understand, maintain, and evolve. When domain-related code is scattered throughout other types of code, it becomes challenging to reason about the business logic and make changes confidently.
Again, we are not here to recap everything that’s already written – the important part to remember is that DDD strongly emphasizes the principle of separation of concerns, proposing a refined four-layer architecture:
The Presentation Layer (UI)
Application Layer: This thin layer sits behind the UI, determining what to do with user inputs. It doesn't contain business logic but rather orchestrates the flow of data and commands between the UI and the Domain Layer.
Domain Layer: This is the heart of the application, containing all the business logic. It's where the rules of the business are encoded, and it operates like a software version of a domain expert.
Infrastructure Layer: This layer handles technical, non-business related requirements such as data persistence, email sending, image rendering, etc.
The Renaissance of DDD
Interestingly, after being first introduced in 2003, DDD was somewhat abandoned for a while. However, it has experienced a renaissance in recent years. Why? Because as systems have grown more complex, more developers have started to understand that building sophisticated software is about much more than just following a set of patterns or architectural guidelines.
DDD's revival reflects a growing recognition in the software community that to build truly effective, maintainable, and evolving systems, we need to think deeply about the problems we're solving, not just the code we're writing. It naturally encourages developers to:
Immerse themselves in the business domain;
Cultivate a ubiquitous language shared by both technical and non-technical team members;
Focus on the core complexity of the business;
Continuously refine and evolve the model as new insights are gained;
Vertical Slice Architecture Ambitions
As we entered the new millennium, the limitations of traditional layered architecture became increasingly apparent. Applications were growing in complexity, teams were expanding, and the horizontal layering approach was starting to show its age. This led to the emergence of vertical architecture, also known as vertical slice architecture or feature-driven design.
Vertical architecture proposes a fundamentally different way of organizing code. Instead of grouping code by its technical function (like presentation, business logic, and data access), it suggests grouping code by feature or business capability. This approach aligns more closely with how stakeholders think about the system and how teams are often organized.

The importance of this separation in the mind of a developer or architect is significant. It leads to different more efficient patterns, different component placements, and a whole new way of thinking about our code. For instance, we immediately move away from the “Repository” pattern – a massive entity responsible for data access. Instead, we embrace patterns like Specification or Query, where each class is responsible for performing a single task from the perspective of the user or business logic.
And here's where it gets really interesting. This vertical approach was a stepping stone to something even bigger: microservices. That's right, the architectural style that has every startup from Silicon Valley to Singapore had its roots in this vertical thinking. Amazon also suggests that vertical slice architecture is the best choice for their AWS Lambda or aligns best with Kubernetes (K8S) and Knative.
Key characteristics of vertical architecture include:
Code is primarily organized around features or business capabilities, rather than technical layers;
Each vertical slice is relatively independent, reducing the ripple effects of changes across the system;
Features can be developed, tested, and deployed more independently;
It naturally supports the concept of bounded contexts from DDD or integration on top of the traditional 3-layered architecture.
Colocating Related Components
One of the most powerful aspects of vertical architecture is how it allows us to place all types related to a specific functionality in one place. Let's take a concrete example: user login functionality. In a vertical architecture, we would create a "Login" folder, which would contain files of different "levels": LoginView.cs, LoginVm.cs, LoginQuery.cs, LoginModel.cs, and so on.
This approach offers a significant advantage: when the requirements for the "login component" change, we still need to modify the view, model, view model, and query, but now all these elements are located in one place. No more jumping between different layers and folders to make a single logical change!
The Why Behind the What
While the technical details of this approach are fascinating (and for those interested, I'd recommend checking out Jimmy Bogard's presentation and his MediatR library), the real power lies in the underlying principle. We should never forget why we break applications into layers in the first place: to make our lives easier.
But what if the current "projection" of our code – the way we organize and think about it – doesn't really make our lives easier? Well, then it might be worth considering other methods of physical decomposition that would address existing problems. This is where vertical slice architecture comes into play.
Hexagonal Architecture: Ports, Adapters, and the Art of Flexibility
It's time to dive into one of the most intriguing architectural patterns to emerge in recent years: the Hexagonal Architecture, also known as Ports and Adapters. This architectural style, introduced by Alistair Cockburn in 2005, offers another powerful approach to structuring applications.
In my opinion, this architecture is an excellent example of how an application's structure should be built. It's like the Swiss Army knife of software design – versatile, elegant, and incredibly practical.
The Core Concept

Hexagonal architecture is fundamentally about separating the business logic from external concerns. Cockburn himself described it:
"Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases."
The main goals of this architecture are:
To separate the business logic from the outside world;
To allow the application to be controlled equally by users, programs, or tests;
To enable development and testing of business logic in isolation from frameworks, databases, or external services;
Key Components – Ports and Adapters
Ports
These are interfaces that define how the application communicates with the outside world. They describe the purpose of the conversation between the two sides.Adapters
These components provide the connection to the outside world. They translate signals from external entities into a form the application can understand, and vice versa.
In simple scenarios, you may only need the basic structure of ports and adapters as described above. However, this architectural concept can be expanded to include more detailed interactions within the application:
Primary (Driving) Adapters: These invoke use cases of the application. They control the application and are typically drawn on the left side of architectural diagrams.
Secondary (Driven) Adapters: These react to actions triggered by the application. They are controlled by the application and are usually drawn on the right side of diagrams.
Old Dog, New Tricks
Now, here's a secret that might surprise you: Hexagonal architecture is by no means a new approach to development. On the contrary, it's merely a generalization of "best practices" – both new and old. I put these words in quotes so that people don't take them too literally. It's like rediscovering ancient wisdom and applying it to our modern challenges.
This type of architecture adheres to the classic idea that developers arrive at when designing applications: separating the application code from other moving parts. The ultimate goal remains the same – achieving high maintainability while minimizing technical debt.
Key benefits of this architecture include:
Allows testing the core application as a black box, using only its ports and mock adapters;
Enables changing business logic without touching adapters;
Facilitates infrastructure upgrades without affecting business logic;
Promotes writing use cases without technical details;
Allows delaying decisions about technical details;
Peeling Back the Layers of The Onion Architecture
If you thought we were done, you'd be mistaken! But don’t worry, this isn't the kind of onion that’ll make you cry – unless you’re already tearing up because your software is just way too complicated.
Jokes aside, the Onion Architecture, introduced by Jeffrey Palermo in 2008, takes the concept of separation of concerns to a whole new level. It's like the Russian nesting doll of software architecture – layers within layers, each with its own distinct purpose.
The Layers of the Onion

Palermo defined four key tenets of Onion Architecture:
The application is built around an independent object model;
Inner layers define interfaces. Outer layers implement interfaces;
Direction of coupling is toward the center;
All application core code can be compiled and run separate from infrastructure;
I believe these principles deserve further exploration. Shall we break them down?
Flipping the Script on Traditional Architecture
Picture your typical layered architecture. You've got your UI at the top, then your business logic, and at the bottom, your data access layer. Each layer depends on the one below it. It's like a house of cards – touch the bottom, and the whole thing comes tumbling down.
Onion Architecture says, "Not on my watch"! It flips this model on its head. Or rather, it turns it inside out. Hence, the onion metaphor.
At the very center of our onion, we have the Domain Model. This is the heart of your application, the core that represents the state and behavior that models the truth for your organization. And here's again an important part that combines all architectural styles – the Domain Model depends on nothing but itself.
Layers of the Onion
As we move outward from the core, we encounter layers with more behavior:
Domain Model Layer: The core of your application;
Domain Services Layer: Interfaces defining operations on domain entities;
Application Services Layer: Implementation of use cases;
Infrastructure Layer: The outermost layer with UI, databases, and external concerns.
In Onion Architecture, all dependencies point inward. Outer layers can depend on inner layers, but inner layers cannot depend on outer layers.
Why is this important? The same old story, it's all about protecting what's most valuable: your core business logic. By ensuring that the inner layers are independent of the outer layers, we create a system that's inherently more flexible and easier to maintain.
If you decide to switch from a REST API to a message queue, or from a relational database to a NoSQL solution, your core business logic remains blissfully unaware. Like changing the tires on your car without affecting the engine, all while the car is still running.
Practical Implications
This architectural style has profound implications for how we develop and maintain software:
In Onion Architecture, the database is not the center – it's external. This is a paradigm shift for those used to thinking about "database applications". Instead, we have applications that might use a database as a storage service, but only through external infrastructure code implementing an interface that makes sense to the application core.
Onion Architecture relies heavily on the Dependency Inversion principle. The application core needs implementations of core interfaces, and if those implementing classes reside at the edges of the application, we need some mechanism for injecting that code at runtime.
Because our core logic is isolated, it becomes much easier to unit test without the need for complex mocks or stubs.
Swapping out infrastructure components becomes less painful, as they're not tightly coupled to our business logic.
It forces developers to think deeply about what truly belongs in the core of the application and what's just an implementation detail.
One of the beauties of Onion Architecture is its versatility. It works well with various approaches, including Domain-Driven Design (DDD), Command Query Responsibility Segregation (CQRS), and even simpler forms-over-data applications. It's not tied to any specific programming paradigm, though it does lend itself well to object-oriented programming (OOP).
The Best of All Worlds in Clean Architecture
The last, but not least, we encounter a pattern that represents the third major attempt to consolidate and refine the circular architectures we've discussed so far: Clean Architecture.

Proposed by none other than Robert Martin (a name that should ring bells for any seasoned developer) in 2012, Clean Architecture is like the grand finale in our architectural show. It takes the core ideas from hexagonal, onion, and other various architectural styles, and distills them into a set of guiding principles that are both powerful and practical.
Each of these original architectural styles had its own flavor, but they all shared a common goal: separation of concerns. They all achieved this by dividing software into layers, with at least one layer for business rules and another for interfaces.
Controversial History of Clean Architecture
At first glance, Clean Architecture is a fairly simple set of recommendations for building applications. But I, and many of my colleagues, strong software engineers, did not immediately understand this architecture. And lately, in chats over the internet, I see more and more misconceptions related to it.
The concept of Clean Architecture didn't emerge overnight. It evolved through a series of articles and presentations by Robert Martin. Here's a brief timeline of its development:
In 2011, Uncle Bob published an article titled "Screaming Architecture." This article proposed that architecture should "scream" about the application itself, not about the frameworks it uses.
Later, he published another article refuting criticisms of clean architecture principles.
The definitive article, "The Clean Architecture," was published in 2012. This article serves as the primary description of the Clean Architecture approach.
To fully grasp the concept, I highly recommend watching Uncle Bob's video presentation on Clean Architecture, which provides additional insights and explanations.
Core Principles and the Dependency Rule
Picture Clean Architecture as a series of concentric circles, each representing a different layer of your application. If Hexagonal Architecture was our first attempt at circular thinking, and Onion Architecture was our second, then Clean Architecture is where we really nail it.
Clean Architecture is based on several key principles:
Testability;
Independence of UI;
Independence of database;
Independence of external frameworks and libraries;
These principles are achieved through a layered architecture and strict adherence to the Dependency Rule.
The Dependency Rule is fundamental to Clean Architecture. It states that source code dependencies should only point inwards. In other words, inner layers should not depend on outer layers. This means that our business logic and application logic should not depend on presenters, UI, databases, or any external frameworks.
Importantly, the names of entities (classes, functions, variables, or any other named software entity) declared in outer layers must not be mentioned in the code of inner layers. This rule allows for building systems that are easier to maintain, as changes in the outer layers will not affect the inner layers.
Layers in Clean Architecture
Clean Architecture typically consists of four main layers:
Entities;
Use Cases;
Interface Adapters;
Frameworks and Drivers;
Let's examine each of these layers in more detail:
Entities
Entities are perhaps the most misunderstood concept in Clean Architecture. They are often confused with simple data transfer objects (DTOs), but this is not accurate.
Entities encapsulate enterprise-wide business rules. These are rules or logic that are common across many applications within the enterprise. If you're working on a single application without a broader enterprise context, Entities represent the business objects of the application, containing the most general and high-level rules.
It's crucial to understand that Entities are not just POJO (Plain Old Java Object) classes that use-cases work with. They must be objects with methods or sets of data structures and functions. The key point is that they contain business logic, not just data.
Doesn't that sound like DDD?
Use Cases
The Use Cases layer contains application-specific business rules. It encapsulates and implements all of the use cases of the system (what system can do). These use cases orchestrate the flow of data to and from the Entities and direct those Entities to use their enterprise-wide business rules to achieve the goals of the use case.
In DDD, Onion Architecture and Hexagonal Architectures this layer is similar to Application Services. Key differences is that Clean Architecture places a stronger emphasis on Use Cases as a separate layer, whereas in some other architectures, this logic might be more spread across layers.
Interface Adapters
This layer contains a set of adapters that convert data from the format most convenient for the Use Cases and Entities, to the format most convenient for some external agency such as a database or the web. It includes things like presenters, views, and controllers.
Once again, we can observe how the idea is aligned with the Ports and Adapters concept from Hexagonal architecture, but with additional meaning.
Frameworks and Drivers
This outermost layer consists of frameworks and tools such as the database, the web framework, etc. Generally, you don't write much code in this layer other than glue code that communicates with the inner circles.
Data Flow and Boundaries
Data flow between layers occurs through Boundaries, which are defined by two interfaces: one for requests and one for responses. These interfaces belong to the inner layer, ensuring that the inner layer does not depend on the outer layer (adhering to the Dependency Rule) while still being able to transfer data to it.
For example, a Controller might call a method on an InputPort interface, which is implemented by a UseCase. The UseCase then returns a response to an OutputPort interface, which is implemented by a Presenter. This way, data crosses the boundary between layers, but all dependencies point inward toward the UseCase layer.
To ensure that dependencies point in the opposite direction of the data flow, the Dependency Inversion Principle is applied. Instead of the UseCase directly depending on the Presenter (which would violate the Dependency Rule), it depends on an interface in its own layer, and the Presenter must implement this interface.
Data that crosses boundaries should be simple structures. They can be passed as DTOs, wrapped in a HashMap, or simply used as method arguments. However, they must always be in a form that is convenient for the inner layer.
It's worth noting that while Clean Architecture is often depicted with four layers, there doesn't have to be exactly four. There can be any number of layers, but the Dependency Rule must always be applied.
Evolution of Ideas
Clean Architecture synthesizes and refines concepts from earlier architectural approaches:
From DDD, it adopts the idea of a rich domain model at the core;
From Hexagonal Architecture, it incorporates the concept of ports and adapters, though reimagined as Interface Adapters;
From Onion Architecture, it maintains the principle of dependency inversion, with all dependencies pointing inward.
What is a Good Architecture, Really?
Now, let's take a step back and ask ourselves: what exactly is software architecture? It's a question that's sparked more debates in the tech world than tabs versus spaces (tabs, obviously).
Defining Software Architecture
In the software industry, "architecture" refers to the most important aspects of the internal design of a software system. It's a hazily defined notion, but one that's crucial for businesses to understand. As Martin Fowler puts it, good architecture is something that supports its own evolution and is deeply intertwined with programming.
A good architecture is characterized by its simplicity and clarity. This is achieved through:
Strict adherence to the architectural concept;
Separation of Input and Output flows;
Strong understandable Naming Conventions;
At this point, I can't help but recall the words of Edsger Dijkstra: “Simplicity is a great virtue but it requires hard work to achieve it and education to appreciate it.”
Additionally, good architecture:
Supports its own evolution: It's designed with the understanding that change is inevitable and allows for easy modifications and extensions.
Is deeply intertwined with programming: It's not a separate, lofty concept but an integral part of the day-to-day coding process.
Reduces cruft: It minimizes elements that impede developers' ability to understand and modify the software.
Enables faster delivery: Counter-intuitively, high-quality architecture leads to faster feature delivery in the long run.
Allows for easy testing: It facilitates thorough testing at multiple levels without sacrificing speed.
Encapsulates implementation details: It hides complexities and limitations of individual components behind well-defined interfaces.
The Cost of Poor Architecture
When architecture is neglected, businesses often face significant challenges. Poor architecture is a major contributor to the growth of junk code – elements of the software that impede the ability of developers to understand the software.
More detailed discussion about “bad code” in one of our previous episodes:

Software that contains a lot of “bad code” is much harder to modify, leading to:
Increased Development Time
As the codebase grows, developers spend more time trying to understand existing code rather than writing new features.
What might have been a simple change in a well-architected system can turn into a weeks-long ordeal.
Developers face an increased cognitive load, having to keep more details in their heads, which slows down development and increases the likelihood of mistakes.
Higher Costs
More developer hours are required for maintenance and new features, translating directly into higher labor costs.
Onboarding of new engineers takes significantly more time, leading to longer period of reduced productivity for new hires.
Poor architecture often leads to inefficient use of computing resources, potentially increasing infrastructure costs.
It becomes inevitable, when businesses need to hire more experienced (and thus more expensive) developers to handle the complexity of a poorly architected system
Reduced Agility
The system becomes resistant to change, making it difficult to pivot with market demands.
Implementing new features or responding to market changes takes longer, potentially causing missed business opportunities.
Developer Velocity is highly impacted with complex interdependencies
More about Developer Velocity Index:Integration with new tools or services becomes challenging, limiting the adoption of new technologies.
All of that lack of flexibility can be a significant competitive disadvantage in fast-moving markets.
Increased Risk and Technical Debt:
Poor architecture often leads to more bugs and security vulnerabilities, potentially resulting in system downtime, data breaches, and loss of customer trust.
The accumulation of suboptimal solutions leads to long-term inefficiencies.
Like financial debt, technical debt compounds over time, making each subsequent change more expensive than the last.
Negative Impact on Team and Business:
Working with a poorly architected system can lead to decreased job satisfaction among developers, potentially resulting in higher turnover rates.
The difficulty in onboarding new team members slows down team expansion and makes it harder to scale development efforts.
The business's ability to deliver value to customers is hampered, potentially affecting market position and revenue.

The Netflix Example of Real-World Architecture in Action

Now, let's take a look at how this principles play out in the real world. Netflix, the streaming giant that's probably responsible for half your weekend plans, faced a killer architecture challenge when building a new app for their Studio Workflows team.
They needed to integrate data from multiple systems using various protocols - gRPC, JSON API, GraphQL, and more. Some of their data was still coming from a monolith destined to be broken up into microservices at an unknown future date.
Netflix solution to the problem was Hexagonal Architecture. Here's why it worked:
Hexagonal Architecture keeps business logic isolated from external concerns like data sources and presentation layers – exactly what was needed.
The architecture allowed them to easily swap data sources without impacting the core business logic. When Netflix hit a read constraint with their monolith, they switched to a newer microservice exposed over GraphQL in just two hours.
The selected design allowed them to delay decisions about internal data storage until they had more information.
Delaying decisions
Let me focus on the last point, that's the whole reason why I decided to take Netflix example as an example of a good architecture in this episode.
Delaying decisions is crucial. But please, don’t confuse this with being indecisive or procrastinating. It's about being smart and not painting yourself into a corner. When you're starting a project, you often have the least amount of information about what you're actually building.
Netflix's approach allowed them to start building and delivering value immediately, without locking themselves into decisions that could come back to bite them in the ass later. They could leverage existing data sources, like their monolith, while keeping the door open to switch to microservices when the time was right.
This is the opposite of what I often see in the real world. Too many teams rush to make every single decision upfront, as if they have a crystal ball that shows them exactly what their system will look like in a year. Spoiler alert: they don't.
By delaying certain decisions, particularly regarding data storage and integration details, you can learn more about actual needs as you build and use the system. When the time comes to make those decisions, you'll have real-world usage data to support your choices, rather than relying on guesswork and assumptions.
TLDR;

Today, we've explored the evolution of application architecture, from the simple three-layered model to the sophisticated designs of today like Hexagonal, Onion, and Clean Architecture. While each style has its unique characteristics, they all share a common thread: the importance of separating concerns and keeping your business logic at the core.
I've learned the hard way that a good architecture is more than just a set of patterns, it's a philosophy that guides your development process. It allows you to build systems that are flexible, maintainable, and adaptable to change. And it's not just about writing code, it's about thinking deeply about the problems you're solving.
In my journey as an engineer and architect, I've come to realize a fundamental truth: good architecture is about alignment. It's about getting everyone – from developers to stakeholders – on the same page. This alignment includes making the right decisions at the right time, but it's so much more. It's about creating a shared vision, fostering effective communication, and ensuring that technical choices support true business goals (which are always hard to identify).
Selecting the right architecture is not rigidly adhering to one methodology. It's about mix and match. In my experience, the real skill of a good architect lies in their ability to blend different architectural styles to fit the unique needs of each project. Sometimes, a pure Hexagonal approach works wonders. Other times, a hybrid of Clean and 3-layer architectures is the ticket. There's no one clear solution, and that's okay.
I've learned to embrace this ambiguity. It's not about finding the perfect architecture – it's about crafting the right one for your specific context. This flexibility can be a game-changer for your organization or business. I've seen firsthand how good architecture can be a real money-saver. Sure, it might take more time upfront and make you spend more on the right people. But the long-term wins? Huge. And these aren't just technical wins – they're business wins.
We've all made mistakes. We’ve over-engineered solutions. We’ve under-engineered others. But each misstep taught us something valuable. The key is to keep learning, keep adapting, and always strive for that balance between structure and flexibility.
In the end, good architecture is our best tool for embracing change. And in our technology world, that's the most valuable skill we can cultivate.
Remember how we started the episode? With those rescue missions and archaeological digs through overcomplicated codebases? Now I encourage you to take a fresh look at your current projects with all these principles in mind and ask yourself:
Is our current architecture truly aligned with our business domain, or are we forcing our domain to fit a chosen architecture? How well does our code structure reflect the mental model of our business experts?
How easily can we adapt to changing business requirements or technological shifts? Does our architecture facilitate or hinder our ability to pivot quickly?
Do we all have the same understanding of the system and what architectural style it follows? Can I understand the software's business value just by briefly looking inside the code?
Always be mindful, you're not just writing code – you're crafting the future, one decision at a time. And that, my fellow tech visionaries, is truly something to be excited about. Until next time!
🔍 Explore more