

Which Company Has Best AI Model End of August 2025? GPT-5 Release
The state of AI wars after the release of GPT-5 and the market reaction that exposed what's wrong with AI evaluation

So GPT-5 dropped yesterday. The internet lost its mind. Again.
Yesterday’s launch was hyped to the stratosphere: OpenAI rolled out its another “most advanced model ever,” promising near-human expertise in everything from coding to medicine. Tech media went into overdrive, Twitter was ablaze with hot takes, and every newsletter seemed to shout that the AI future had arrived… again.
By the way, that’s my favorite graph explaining how much better the new version of GPT is:
The hype machine has its own gravitational pull, and reality doesn’t always bend to match it. Case in point: within minutes of the presentation ending, something curious happened in the prediction markets.
Selling a dollar for 79 cents!
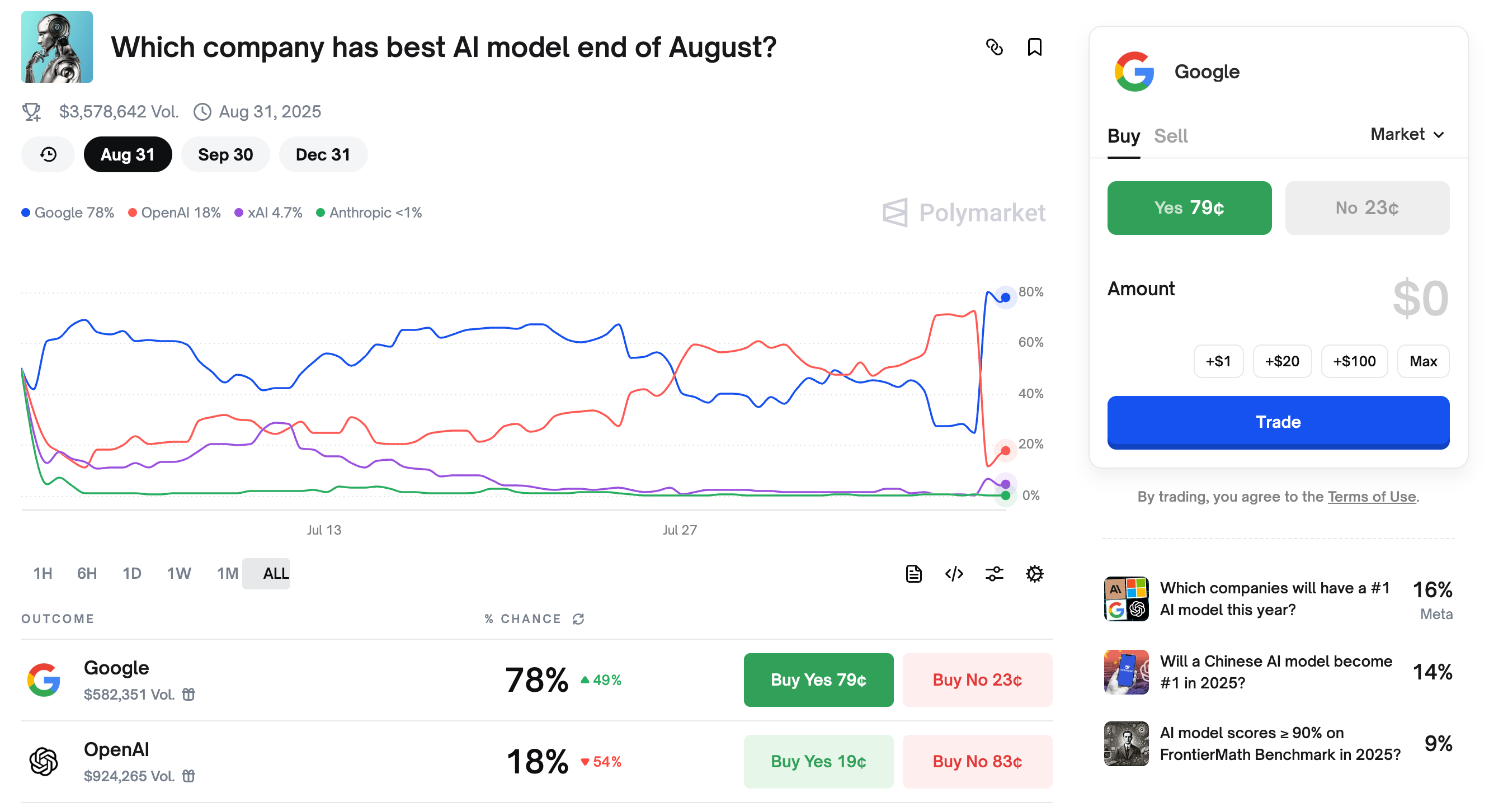
Someone dropped me a link to a Polymarket prediction page, where people bet money on their forecasts. This particular page is about which model will be the best at the end of August. Yesterday, this market flipped: before the GPT-5 presentation, OpenAI was in the lead, but almost immediately after it began, its “shares” started being sold off heavily, and Google surged ahead.
Could the presentation really have been such a failure? In fact, no – this market didn’t depend on the presentation at all. It’s important to read exactly how the best model will be determined. The criterion is: top-1 on LMArena (where people ask a question, get two answers from different models, and choose the one they like more).

But there’s one “but”: the evaluation will be done without Style Control – meaning, without adjusting for the style of the answers. To be precise, it’s been known for a while that, on average, the longer an answer is and the more formatting it has (including bold text and lists), the more voters tend to like it.
That’s why, as far back as 11 months ago, LMArena introduced Style Control. For a long time, it was used in calculations, but wasn’t the default method (I don’t know why – to me, the logic is clear). In May of this year, this finally changed: now models are penalized for graphomania and the urge to make lists with bold highlights.
But since this market was created earlier, the evaluation criteria there is the “old” one – without that penalty. And according to it, GPT-5 and Gemini 2.5 Pro share first place (1481 points for Gemini versus 1460 for OpenAI’s model – not a statistically significant difference). So what really happens? The rules say that in the case of a tie, the winner is the model from the company whose company name (not the model name) comes first alphabetically! This way, Google > OpenAI.
Thus, the only thing influencing the market was the Arena results, which became known at the time of the presentation. And not even the default leaderboard (where OpenAI is in first place with a statistically significant lead), but the outdated Without Style Control results.
If they had announced at the presentation that GPT-5 had found a cure for cancer, or, conversely, had invited a stand-up comedian to host it, nothing would have changed – because only the Arena results matter.
Essentially, the market turned into a prediction of “will OpenAI release an update in the next 23 days that surpasses the just-unveiled model in human evaluation without accounting for biasing factors.” I think the answer is no, so I bought shares in Google 🤓
To think deeper, we're measuring AI capabilities using systems that reward the wrong things, leading to massive misallocation of attention and resources in the AI wars. Style beats substance, and alphabetical accidents determine "winners."
At the same time, reading reviews and reactions to GPT-5's release, I notice one thing: people discovered with surprise, but some relief that they'll still have to work even in 2027.
🔎 Explore more: