

AI Reasoning: Are Language Models Faking Their Logical Abilities?
Apple’s latest study challenges AI reasoning in math – are LLMs truly capable of logic, or are they just mimicking patterns? Explore the findings and new benchmarks testing AI’s limits!

Hey there and welcome back to another episode of Tech Trendsetters – the warm place where we chat about cool stuff happening in technology, science, and AI. Did you ever wonder just how smart AI really is? Today we're taking a look at a fascinating question: what are the limits of AI when it comes to math and reasoning?
We'll explore what Large Language Models can (and can't) figure out.
Is there an actual “reasoning” happens in LLMs, especially mathematical reasoning?
And how robust are LLMs to these mathematical tasks and reasoning, or they doing just pair matching and remember things down?
Just a few weeks ago, a team of sharp minds from Apple released research that's got everyone talking – and that’s the theme of today’s episode. And yes, it’s good to see Apple finally moving into the research space! They've taken a magnifying glass to the logical reasoning abilities of LLMs, and to be honest, the results are somewhat contradictory.
The Challenge of Mathematical Reasoning
Large Language Models have become the talk of the tech world, and for good reason. These AI systems can engage in conversations, solve business problems, and even generate code. But when it comes to math, things get interesting. How to evaluate AI? Benchmarks!
Remember one of our episodes on LLM benchmarks? One benchmark we touched on was GSM8K, and it's taking center stage in today's episode.

The GSM8K benchmark, created in 2021, has been the go-to test for measuring an AI's math skills. It's a collection of 8,000 grade school math problems, ranging from simple to moderately complex, each task has from 2 to 8 actions with four basic operations (+, −, ×, ÷).

Now, you'd think these problems would be a breeze for AI, because we call it “AI” after all, right? And initially, it seemed that way. Top models like GPT-4o were scoring an impressive 96% on these tests. As someone who's been following AI development closely, I trusted the benchmark but had a feeling that something might not be right, because I don’t see that level of sharpness when, for example, I try to count my calorie intake in ChatGPT. Are these AIs really that smart, or is something else going on?
This is where Apple's research team comes in. Instead of just accepting these high scores at face value, they decided to dig deeper. They asked a crucial question that, frankly, more of us in the tech community should be asking:
Are these AIs actually reasoning through the problems, or are they just really good at recognizing patterns?
It's a distinction that matters a lot. As humans, when we solve a math problem, we use logical thinking. We break down the problem, apply rules we've learned, and work step-by-step towards a solution. But AIs might be doing something entirely different.
The problem with the original GSM8K test is that it's static. The same questions, with the same numbers and names, are used over and over. This means an AI could potentially just memorize the patterns of questions and answers without truly understanding the math behind them.
It reminds me of how some students (and me in a past) can ace standardized tests by memorizing answer patterns, without really grasping the underlying concepts. This possibility in AI testing can be really concerning.
GSM-Symbolic: A New Benchmark
That's why I find Apple's new approach with GSM-Symbolic so intriguing. In a study “GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models”, they've essentially created a way to change up the questions while keeping the core math the same.
For example, if the standard problem is phrased as, "if Beth bakes 4x2 dozen batches of cookies in a week," they can generate numerous similar problems, such as, "if Dmitry bakes 5x3 dozen batches of cupcakes in two weeks." While the names, numbers, and context change, the underlying mathematical problem remains consistent.

Here's how the research team did it:
They took 100 problems from the original GSM8K dataset and turned them into templates;
In these templates, they highlighted elements that could be changed: names, numbers, and even some contextual details;
They then generated 50 variations of each template, creating a total of 5,000 new problems;
The genius of this approach is that it allows us to test whether AI can truly reason through math problems or if they're just really good at pattern recognition. If an AI understands the underlying mathematical concepts, it should be able to solve these new variations just as well as the original problems.
To make things even harder, the team didn't stop at just changing names and numbers. They also created more complex variations:
GSM-Symbolic-Minus-1: They removed one step from the original problem, making it slightly easier;
GSM-Symbolic-Plus-1 and Plus-2: They added one or two extra steps, increasing the difficulty;
GSM-NoOp: They added information that seems relevant but doesn't actually affect the solution;
This last variation, GSM-NoOp, is particularly clever. It tests whether AI can distinguish between relevant and irrelevant information – a key aspect of true reasoning.
Does AI Have Real Math Reasoning?
The short answer? Not quite. At least, that’s what we can conclude from the Apple team's study. It reveals that current LLMs, despite their impressive performance on standard benchmarks, fall short of demonstrating true mathematical reasoning akin to human problem-solving.
As complexity increases, performance declines. But let's look into the details that led to this conclusion.
Performance Variability
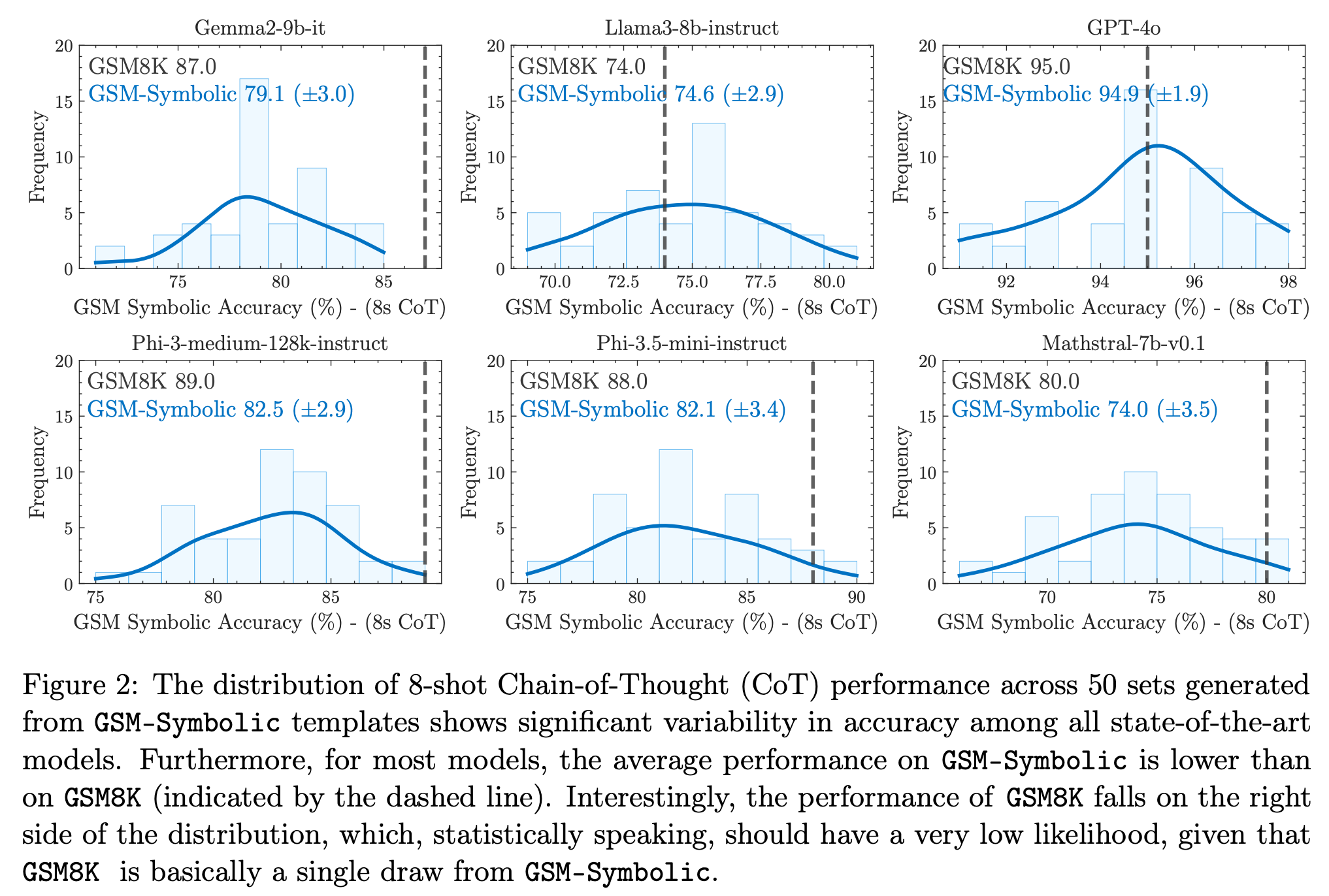
The researchers found significant performance variability across different instantiations of the same question. When they changed the names, numbers, or context of a problem while keeping the underlying math the same, the AI's performance decreased, and for some models decreased significantly.
For instance, according to the picture above, some models showed a performance range of over 12-15% between their worst and best attempts on different versions of the same problems.
This way it raises questions about potential data contamination – the possibility that some of these questions or similar ones were part of the models' training data. If the AI has seen these or closely related problems during its training, it obviously affects performance when evaluated against standard benchmarks, like GSM8K.
Sensitivity to Numerical Changes

The models showed more robustness when only names were changed in the problems. However, when numerical values were altered, the performance drop was more significant. This suggests that models might be relying more on recognizing patterns in numbers rather than truly understanding the mathematical relationships involved.
It's not surprising at all and reminds me that AI might be good at mimicking problem-solving behaviors but struggles with true generalization and adaptability, which are crucial for real-world applications.
Difficulty Scaling

As the number of steps or clauses in a problem increased (like in the GSM-Symbolic-Plus-1 and Plus-2 variations), the performance of all models declined, and the variance in their performance increased. This indicates that LLMs struggle with increased complexity in mathematical reasoning tasks.
However, it's important to note that humans also tend to struggle more with increased problem complexity. For instance, if you ask me to solve a math problem, I might manage it well initially, but if you rephrase the same problem in a more complex or abstract way, or add more steps to think through, I'd likely find it much more difficult to solve.
Nevertheless, this seems to be in line with the hypothesis that models are not performing formal reasoning, as the number of required reasoning steps increases linearly, but the rate of drop seems to be faster.
The GSM-NoOp Challenge

Perhaps the most interesting part came from the GSM-NoOp variation. When seemingly relevant but ultimately irrelevant information was added to problems, there were substantial performance drops across all models – even the most advanced ones. Some models saw their accuracy plummet by up to 65%!
This shows that these AI models struggle to discern what information is actually relevant to solving a problem. But here , it's worth noting again – humans, especially under time pressure or without explicit instruction, might also struggle to consistently ignore irrelevant information in problem-solving scenarios.
Limitations of Pattern Matching
Interestingly, even when models were given multiple examples of the same question or examples containing similar irrelevant information, they still struggled to overcome these challenges. This suggests us that the issue goes deeper than just needing more context or examples. Most probably the limitations are in how these models process and reason about mathematical problems.
At this point you might assume that LLMs are simply “pattern-matching” machines. However, if you think about it, the finding above challenges this idea. If they were truly excellent at pattern matching, we might expect them to quickly adapt to ignoring irrelevant information when shown multiple examples. The fact that they don't – suggests a more complex interplay between their training and problem-solving approaches.
Does AI Have Real Reasoning?
The Apple team's study on GSM-Symbolic aimed to answer a fundamental question about AI capabilities:
Do Large Language Models truly reason, or are they just really good at pattern matching?
However, as we dig deeper into their methodology and findings, we uncover some critical issues in how we approach AI research and evaluation.
The Definition Dilemma

The study claims to investigate whether LLMs are capable of "real reasoning." But here's the catch – they never clearly define what "real reasoning" means. This is a fundamental flaw in the research methodology. How can we test for something if we haven't defined what that something is? Or even if we go deeper, what defines human reasoning? Is it the vast amount of information and knowledge we've accumulated (trained on) throughout our lives, or is it something inherent?
If we apply the same standards to humans we apply for LLMs, we might end up concluding that humans aren't reasoning either. Many people would struggle with the more complex GSM-Symbolic problems or be misled by irrelevant information. Does this mean humans aren't reasoning? Or does it suggest that our definition of reasoning needs to be more nuanced?
The Synthetic Data Trap
The GSM-Symbolic dataset, while innovative, introduces a potential bias. By creating synthetic problems that may not reflect real-world scenarios, we're testing LLMs on a distribution of problems that's fundamentally different from what they were trained on – and potentially different from what humans would consider "normal."
This raises another crucial question: Are we really testing mathematical reasoning, or are we testing the ability to handle artificial, potentially nonsensical scenarios? The reason for this is that GSM-Symbolic contains a large number of problems that simply cannot exist in real life, like buying 1,000 liters of milk and only one pack of cereal. LLMs were trained to reflect human reality, and this simply is not.
The performance drop in LLMs could be partly attributed to this mismatch between training data (based on real-world text) and test data (synthetic problems).
The Scaling Illusion
The study presents performance drops across models as if they're directly comparable. However this can be misleading. A 1% drop for a model with 99% accuracy is much more significant than a 1% drop for a model with 50% accuracy.

This directly related to a question of how we interpret performance metrics for AI models, especially when it comes to scaling.
Just to provide an example: imagine two models. Model A with 99% accuracy and Model B with 10% accuracy. If both models experience a 1 percentage point drop in performance:
Model A drops from 99% to 98% accuracy;
Model B drops from 10% to 9% accuracy;
Now, let's look at this from an error rate perspective:
Model A's error rate increases from 1% to 2% – a 100% increase in errors;
Model B's error rate increases from 90% to 91% – only about a 1.1% increase in errors;
This means for high-performing models, even small drops in accuracy can represent massive increases in error rates.
The Pattern Matching Paradox
Interestingly, while the study set out to show that LLMs rely on pattern matching rather than reasoning, it inadvertently demonstrated that LLMs are actually quite bad at pattern matching in certain contexts. Even when given multiple examples of how to ignore irrelevant information, many models failed to do so consistently. This challenges both the "reasoning" and "pattern matching" hypotheses. Most probably our understanding of LLM capabilities is still limited.
The Human Benchmark Problem
Throughout the study, there's an implicit comparison to human-level reasoning. However, we don't have a clear benchmark of how humans would perform on these exact tasks, especially the more complex or artificial ones. Take this problem as an example and imagine you were asked this on the street:

Without this comparison, it's hard to say whether the LLMs are falling short of human-level reasoning or simply exhibiting human-like limitations.
Rethinking the Nature of AI Reasoning

As we move closer to the end of discussion on this GSM-Symbolic study, I find myself reflecting on the broader themes of this research. It's a classic scenario in science, though: researchers try to improve benchmarks and uncover unexpected results that spark even more contradiction.
On one hand, I applaud the Apple team for their effort to create a more robust benchmark. They saw potential flaws in GSM8K and tried to address them. That's how science progresses. But on the other hand, their results have opened up more questions than they've answered.
This study has made me think of a fundamental question: What do we really mean when we talk about "reasoning" in AI? And should AI reasoning mirror human reasoning, or should it be something entirely different?
As humans, our reasoning is deeply intertwined with our experiences, biases (which we often discuss here), and the quirks of our neural architecture. AI (neural networks) started as an attempt to mimic the human brain. We built these systems inspired by our own neural architecture, hoping to recreate human-like intelligence. And in many ways, the “flaws” observed in LLMs, especially on the GSM-Symbolic tasks, are very human-like.
But as AI has evolved, it's taken on characteristics that diverge from human cognition. They can recognize patterns in huge datasets that would take humans lifetimes to analyze. So we find ourselves at an interesting crossroads: AI is both inspired by human cognition and fundamentally different from it.
Not only in the study at hand, but you can also see people in the AI space using phrases like:
as we strive to create systems with human-like cognitive abilities or general intelligence.
This language reveals an uncertainty. We're developing AI systems without a clear, unified vision of what we're ultimately trying to achieve. Are we aiming for human-like intelligence, or something alien, that spreads beyond our understanding?
The truth is, we don't yet fully understand human intelligence, let alone have a clear definition of what "artificial general intelligence" means. This makes it challenging to set concrete goals for AI development or create truly meaningful benchmarks.
Thanks for joining me today! We started this episode wondering if AI is really a math genius, and ended up discovering it's both more and less capable than we thought.
Who knows? Maybe one day we'll create an AI that's so good at math, it'll solve all our problems... and then create new ones we can't even understand! Until then, stay safe and curious, and don't forget to occasionally share this episode with your friends! See you next time!
🔎 Explore more: