

How to Build AI Agents That Actually Work: The 12-Factor Check
The honest guide to AI agents: why most fail, what actually works, and how to build reliable LLM applications without a PhD.

Everyone’s building agents now. Or at least they claim they are.
The truth? Most of these “agents” are either fancy chatbots with delusions of grandeur or Rube Goldberg machines that break the moment you push them into production. This is a rerun. We called them “intelligent assistants” in 2016. Before that, “expert systems.” Same hype cycle. Different wrapper.
But! some people are actually building agents that work. Not agents that demo well. Agents that ship. That handle real workloads. That don’t collapse into a pile of prompt spaghetti when users do something unexpected.
So recently I watched a talk by Dexter Horthy, founder of HumanLayer (backed by Y Combinator), where he breaks down patterns for building reliable LLM applications. What is his central thetis? Stop treating agents like mystical AI constructs. They’re just software. And if you understand “switch” statements and “while” loops (which you probably do) you can build them.
The catch is that you have to truly own your system end to end. Frameworks can accelerate the first 70% of development – they give you quick start, conventions, and shortcuts that get something working quickly. But the closer you get to 100%, the more those abstractions become constraints. You end up reverse-engineering the framework itself just to make it do what you actually need. And real engineering starts where the framework stops, when you’re actually forced to understand, design, and optimize the underlying mechanics instead of relying on someone else’s defaults.
Dexter calls that approach the “12-Factor Agents,” inspired by the 12-Factor App methodology that Heroku pioneered for cloud-native applications. It’s a set of principles for building agents that are reliable, maintainable, and, most importantly, actually solve problems.
The GitHub repo hit 4,000 stars in two months (now it’s already at 16k). Front page of Hacker News all day. Clearly, people are tired of the agent snake oil.
I’m going to walk you through why most agent projects fail, what actually works, and how to apply these 12 factors without getting lost in framework hell.
The Framework Trap and the 70-80% Problem
Here’s how it goes down.
You decide to build an agent. You know what it needs to do. You’re a developer, so you reach for libraries because you’re not insane – you don’t write everything from scratch. The framework promises to handle the complexity. Routing. Memory. Tool calling. All the hard stuff.
And it works! Sort of. You get to 70-80% quality fast enough to impress your CEO and suddenly you’ve got six more people on your team.
Then, when you have something in production, hard part comes.
That last 20-30% is not a gentle slope. It’s a cliff. To cross it, you’re seven layers deep in a call stack trying to reverse-engineer how prompts get built, where tools get injected, why the context window is formatted this way and not that way. The framework that was supposed to save you time is now costing you debugging hours you’ll never get back.
I’ve been there. We’ve all been there.
Dexter talks about his first agent project – a DevOps agent that would run make commands and build projects. Sounded great. Didn’t work. The agent kept doing things in the wrong order, so he kept adding detail to the prompt. More context. More instructions. More explicit step-by-step guidance. By the end, he’d written out the exact order of build steps in prose.
At which point he realized: “I could have written the bash script to do this in 90 seconds.”
Not every problem needs an agent.
This is the part that gets lost in all the hype. LLMs are powerful. But they’re not magic. And they’re definitely not free. Every time you reach for an LLM when a deterministic function would work, you’re introducing latency, cost, and unreliability. You’re trading predictability for flexibility you might not actually need.
Dexter spent months talking to 100+ founders and engineers building production agents. Pattern recognition kicked in. Most production agents weren’t that “agentic” at all. They were mostly software with small, focused LLM components sprinkled in strategic places. The magic wasn’t in the autonomy – it was in the integration.
The part I always like the most: you don’t need an AI background to build agents. You need software engineering fundamentals. The same principles that made apps work in the cloud a decade ago apply to making agents work now.
The 12 Factors That Separate Real Agents from Vaporware
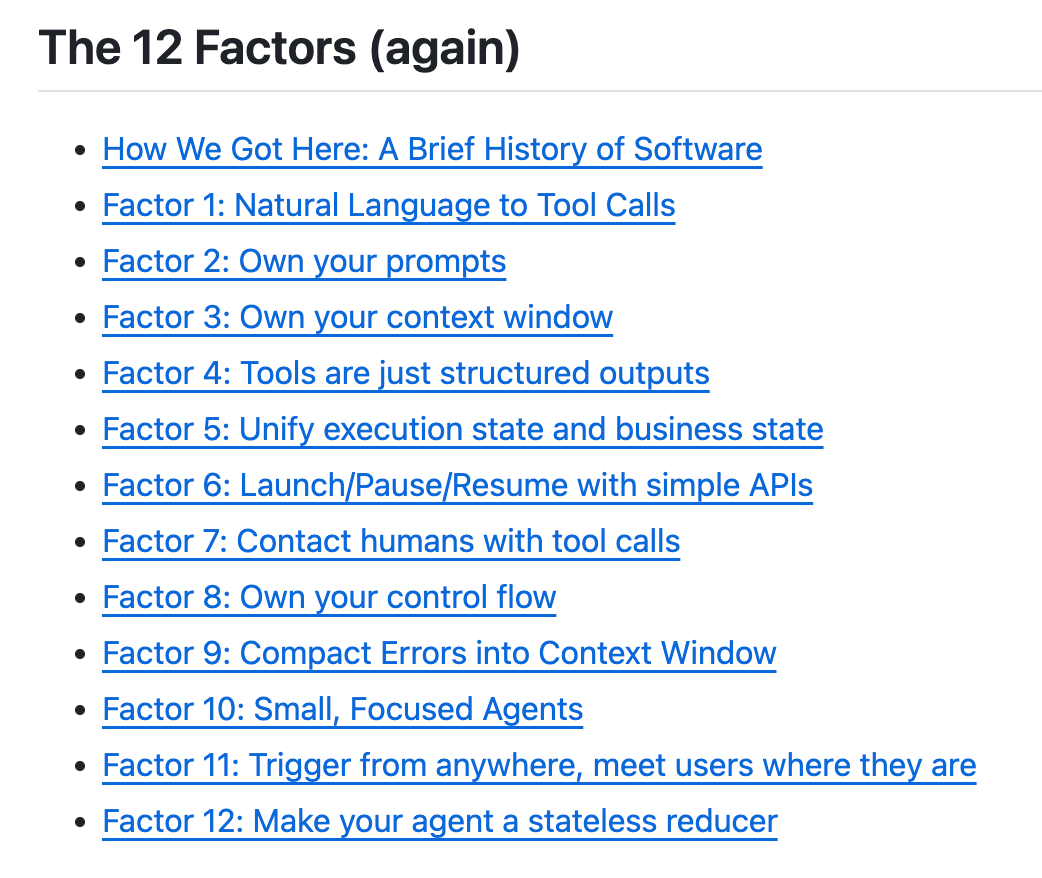
That’s where all of these observations were combined into “12 factors”. Principles you can apply wherever they make sense.
I’ve grouped related factors together for simplicity, but if you’d like to explore each one in detail, you can visit the original source via the link below.
Natural Language Is Just JSON
Most production agents are mostly deterministic code, with LLM steps sprinkled in at just the right points
That’s the reality nobody talks about.
Factor 1 (Natural Language to Tool Calls) is straightforward: natural language gets converted to structured tool calls. You ask the agent to “schedule a meeting with Sarah next Tuesday at 2pm” and you get JSON back:
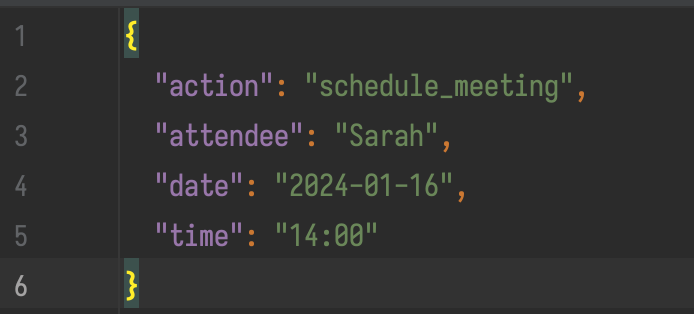
This is the “actual” magic behind AI agents.
Which brings us to Factor 4 (Tools are just structured outputs) – and this is where Dexter gets provocative. He says “tool use is harmful.” Not the concept of agents interacting with the world. The abstraction of treating tools as some mystical interface.
What’s actually happening: Your LLM outputs JSON. Your code parses it. Your code executes something. Maybe you feed results back. That’s it.
Very straightforward. No special sauce. Just:
Structured outputs from the model;
Regular code that does things;
Optional feedback loop;
When you understand this, you stop fighting your tools. You stop trying to make the LLM “smarter” about calling APIs. You make your system clearer about what those API calls mean.
In my experience building internal agents also changed my perspective. I stopped asking “how do I make the agent better at using tools” and started asking “how do I make my tools easier to describe as JSON schemas.”
Different question. Better results.
Own Your Inputs, Own Your Outputs

Having full control over your prompts gives you the flexibility and prompt control you need for production-grade agents.
Frameworks give you good prompts. Sometimes great prompts. They’ve done the research. They’ve tested thousands of variations. You’ll get to 70-80% quality fast.
Then you need 95%. And that’s when you realize you’re screwed.
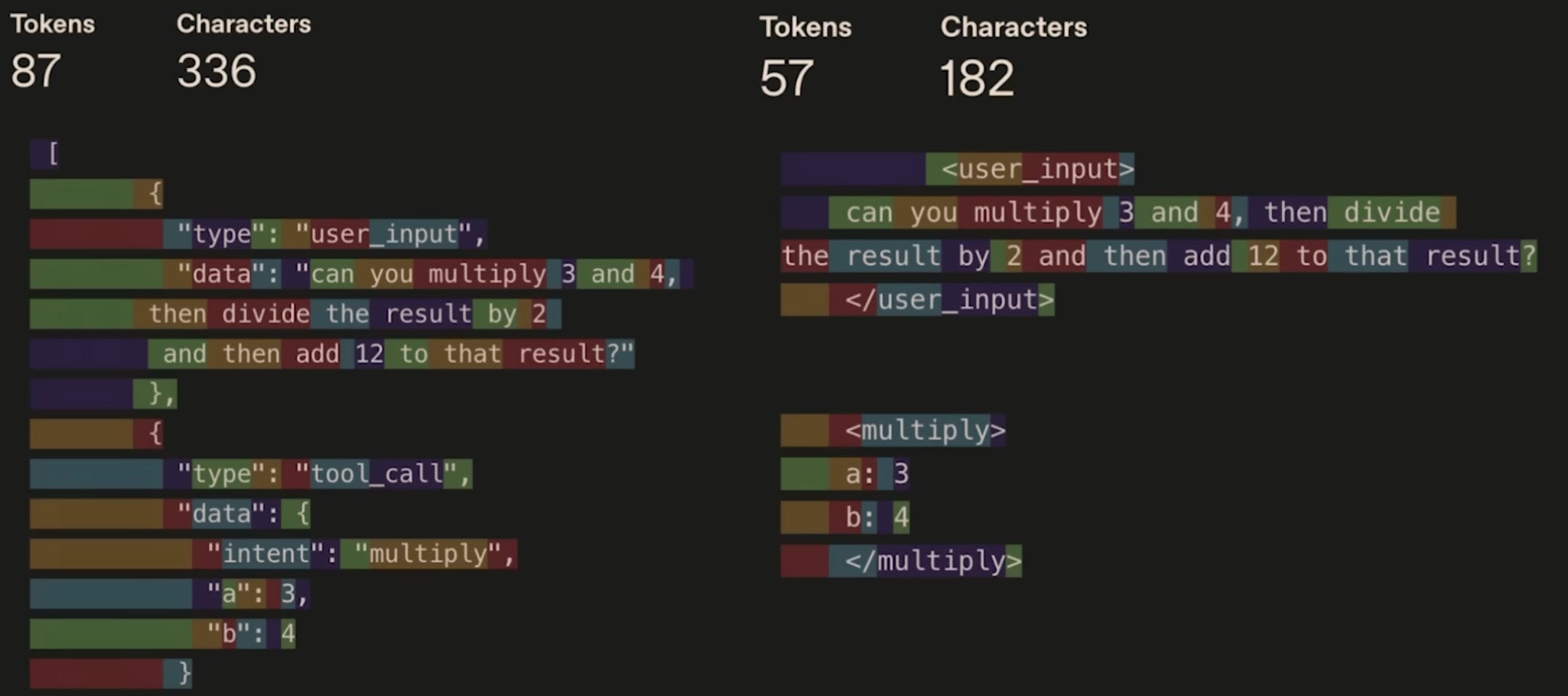
Every single token matters. When you’re trying to get reliable behavior from an agent that runs unsupervised, the difference between “analyze the data” and “review the following data points” can be the difference between working and not working.
You need to A/B tests. You need to iterate. You need to see exactly what’s being sent. Most importantly: when the model changes (and it will change), you need to adapt the prompt.

Can’t do that if your prompt is buried seven layers deep in someone else’s code.
Your prompts are the primary interface between your application logic and the LLM. Treat them like first-class code. Version control them. Review them. Document why you made specific choices.
Point is: we should see them, change them, test them independently.
Own your context window.

Own the context window, squeezing traces and error summaries into it so the model can self-heal.
Context window is not exactly a chat history. It’s everything: your prompt, your memory, your RAG results, your execution trace, your error messages. It’s the entire universe the LLM sees when making decisions.
Most frameworks manage this for you. They build up message arrays in OpenAI format. They handle conversation history. Convenient.
Until you need to optimize token usage. Or summarize old context. Or format things specifically for your domain. Or debug why the agent forgot something important.
You can build agents that format their context as timelines. As XML structures. As compact state summaries. Because owning the context gives a great flexibility.
There are examples where companies reduced context size by 60% by switching from standard message format to a custom trace format. Same information. More token-efficient. The model actually performed better because the signal-to-noise ratio improved.
Point is: You can’t improve tokens out without controlling tokens in. Period.
Control Flow Is Where You Actually Build Reliability
Here’s what everyone tries first: simple agent loop. Pass event to LLM. Get tool call. Execute. Append result to context. Repeat until done.
Works great for demos, and again – falls apart in production.
Why? Long context windows get messy. The model loses track. Quality degrades. And the promise of “just give it tools and let it figure things out” becomes a debugging nightmare.
Factor 8 (Own your control flow).
An agent is just:
A prompt (tells the model how to pick the next step);
A switch statement (routes JSON output to functions);
Context building (assembles what to feed back);
A loop (determines when to exit);
That’s it. And as I mentioned before (most production agents aren’t actually that agentic) they’re mostly deterministic code with LLM steps sprinkled in at decision points.
When you own the control flow, you can:
Break early when you detect problems;
Switch between execution paths based on state;
Summarize context when it grows too large;
Add debugging and observability wherever needed;
Pause when waiting for external input;
Can’t achieve any of this if your control flow is abstracted away.
Unified State and Proper APIs
Persist execution state right next to business state so restarts are idempotent; expose launch/pause/resume endpoints.
Don’t overcomplicate state management. Your agent’s state is just... state. Maybe it’s all in one database table. Maybe you separate some pieces. But don’t let frameworks dictate your architecture.
And please – build proper APIs. An agent is a program. You should be able to:
Start it;
Check its status;
Pause it (serialize state to database);
Resume it (load state and continue);
Stop it;
For example, when the deployment agent waits for human approval, it serializes everything and goes to sleep. When the approval comes back via Slack webhook, it wakes up and continues. The agent doesn’t even know it paused.
This isn’t novel. Just a basic software engineering. But a lot of agent frameworks don’t make this easy.
Humans Aren’t Edge Cases

This is the point I like the most, because even for me, it completely changed my perspective.
Route high-stakes steps to humans as a first-class tool call, not as an afterthought. If an agent is handling something that involves risk, ambiguity, or empathy, bringing a human into the process isn’t a weakness – it’s a design strength.
Most frameworks treat human interaction as separate from tool calling. That’s backwards. Human input should be integrated directly into the agent’s reasoning chain, just like any other API or function call.
Here where we’re naturally coming to the Factor 7 (Contact humans with tool calls).
When your agent needs clarification, it calls the request_input tool. When it needs approval for something risky, it calls the request_approval tool. When something’s wrong, it calls the escalate tool.
Why does this matter? Because it keeps human interaction inside the same decision-making loop. The model decides based on context: Do I have enough information? Is this risky? Should I proceed or ask for help?
And when you combine this with Factor 6 (pause/resume), you get durable workflows. Agent decides it needs input. Calls the tool. Pauses. Waits minutes, hours, or days. Human responds. Agent resumes. Continues.
In my humble opinion this is the only way how you can build agents people actually trust.
Build Micro-Agents the Way We Build Microservices
Stop trying to build one agent that does everything. Small, focused agents beat monoliths.
You may still have mostly deterministic workflows. But at key decision points, you insert small agent loops. These handle the parts that benefit from natural language reasoning. Then you go back to regular code.
Why does this work?
Manageable context (3-10 steps means short context windows);
Clear scope (each micro-agent has one job);
Easy debugging (problems are isolated to specific agents);
Reliable execution (smaller scope = higher reliability);
“What if models get better and can handle 100-step workflows?” Sure. Maybe. But even then, you’ll want focused components. Smaller pieces are easier to test, debug, monitor, and improve.
This is the microservices moment for AI. Break things down. Own each piece. Compose them into larger systems.
The Real Question: What Are You Optimizing For?
Look, we all don’t build agents because they’re cool. We build them because they solve real problems, save money and save real time.
Even if LLMs continue to get exponentially more powerful, there will be core engineering techniques that make LLM-powered software more reliable, scalable, and easier to maintain.
Will GPT-6 or Claude-5 or whatever comes next be smarter? Sure. Will they need less hand-holding? Probably. But you’ll still need these principles:
Control over your prompts and context;
Clear ownership of control flow;
Proper state management;
Good error handling;
Human-in-the-loop design;
Focused, composable components;
Because even with better models, production reliability comes from engineering, not from hoping the AI figures it out.
The jump from prototype to production-grade – getting to 70% in three days, then spending three months trying to hit 90% is still a real problem.
The fastest way to get high-quality AI software in the hands of customers is to take small, modular concepts and incorporate them into existing products.
Start small. Pick one factor. Apply it. Measure the difference. Then pick another.
You don’t need to adopt all 12 factors tomorrow. You don’t need to rewrite everything. You just need to stop treating agents like alien technology and start treating them like software.
Because that’s what they are. Software that happens to call an LLM at key points.
Own your code. Control what matters. Build systems that work.
🔎 Explore more: